![[banner]](images/banner.jpg "Cohansey River, Fairfield, New Jersey")
Correlation and linear regression each explore the relationship between two quantitative variables. Both are very common analyses.
Correlation determines if one variable varies systematically as another variable changes. It does not specify that one variable is the dependent variable and the other is the independent variable. Often, it is useful to look at which variables are correlated to others in a data set, and it is especially useful to see which variables correlate to a particular variable of interest.
The three forms of correlation presented here are Pearson, Kendall, and Spearman. The test determining the p-value for Pearson correlation is a parametric test that assumes that data are bivariate normal. Kendall and Spearman correlation use nonparametric tests.
In contrast, linear regression specifies one variable as the independent variable and another as the dependent variable. The resultant model relates the variables with a linear relationship.
The tests associated with linear regression are parametric and assume normality, homoscedasticity, and independence of residuals, as well as a linear relationship between the two variables.
Appropriate data
• For Pearson correlation, two interval/ratio variables. Together the data in the variables are bivariate normal. The relationship between the two variables is linear. Outliers can detrimentally affect results.
• For Kendall correlation, two variables of interval/ratio or ordinal type.
• For Spearman correlation, two variables of interval/ratio or ordinal type.
• For linear regression, two interval/ratio variables. The relationship between the two variables is linear. Residuals are normal, independent, and homoscedastic. Outliers can affect the results unless robust methods are used.
Hypotheses
• For correlation, null hypothesis: The correlation coefficient (r, tau, or rho) for the sampled population is zero. Or, there is no correlation between the two variables.
• For linear regression, null hypothesis: The slope of the fit line for the sampled population is zero. Or, there is no linear relationship between the two variables.
Interpretation
• For correlation, reporting significant results as “Variable A was significantly correlated to Variable B” is acceptable. Alternatively, “A significant correlation between Variable A and Variable B was found.” Or, “Variables A, B, and C were significantly correlated.”
• For linear regression, reporting significant results as “Variable A was significantly linearly related to Variable B” is acceptable. Alternatively, “A significant linear regression between Variable A and Variable B was found.”
Packages used in this chapter
The packages used in this chapter include:
• psych
• PerformanceAnalytics
• DescTools
• ggplot2
• rcompanion
The following commands will install these packages if they are not already installed:
if(!require(psych)){install.packages("psych")}
if(!require(PerformanceAnalytics)){install.packages("PerformanceAnalytics")}
if(!require(DescTools)){install.packages("DescTools")}
if(!require(ggplot2)){install.packages("ggplot2")}
if(!require(rcompanion)){install.packages("rcompanion")}
Examples for correlation and linear regression
Brendon Small and company recorded several measurements for students in their classes related to their nutrition education program: Grade, Weight in kilograms, intake of Calories per day, daily Sodium intake in milligrams, and Score on the assessment of knowledge gain.
Data = read.table(header=TRUE, stringsAsFactors=TRUE, text="
Instructor Grade Weight Calories Sodium Score
'Brendon Small' 6 43 2069 1287 77
'Brendon Small' 6 41 1990 1164 76
'Brendon Small' 6 40 1975 1177 76
'Brendon Small' 6 44 2116 1262 84
'Brendon Small' 6 45 2161 1271 86
'Brendon Small' 6 44 2091 1222 87
'Brendon Small' 6 48 2236 1377 90
'Brendon Small' 6 47 2198 1288 78
'Brendon Small' 6 46 2190 1284 89
'Jason Penopolis' 7 45 2134 1262 76
'Jason Penopolis' 7 45 2128 1281 80
'Jason Penopolis' 7 46 2190 1305 84
'Jason Penopolis' 7 43 2070 1199 68
'Jason Penopolis' 7 48 2266 1368 85
'Jason Penopolis' 7 47 2216 1340 76
'Jason Penopolis' 7 47 2203 1273 69
'Jason Penopolis' 7 43 2040 1277 86
'Jason Penopolis' 7 48 2248 1329 81
'Melissa Robins' 8 48 2265 1361 67
'Melissa Robins' 8 46 2184 1268 68
'Melissa Robins' 8 53 2441 1380 66
'Melissa Robins' 8 48 2234 1386 65
'Melissa Robins' 8 52 2403 1408 70
'Melissa Robins' 8 53 2438 1380 83
'Melissa Robins' 8 52 2360 1378 74
'Melissa Robins' 8 51 2344 1413 65
'Melissa Robins' 8 51 2351 1400 68
'Paula Small' 9 52 2390 1412 78
'Paula Small' 9 54 2470 1422 62
'Paula Small' 9 49 2280 1382 61
'Paula Small' 9 50 2308 1410 72
'Paula Small' 9 55 2505 1410 80
'Paula Small' 9 52 2409 1382 60
'Paula Small' 9 53 2431 1422 70
'Paula Small' 9 56 2523 1388 79
'Paula Small' 9 50 2315 1404 71
'Coach McGuirk' 10 52 2406 1420 68
'Coach McGuirk' 10 58 2699 1405 65
'Coach McGuirk' 10 57 2571 1400 64
'Coach McGuirk' 10 52 2394 1420 69
'Coach McGuirk' 10 55 2518 1379 70
'Coach McGuirk' 10 52 2379 1393 61
'Coach McGuirk' 10 59 2636 1417 70
'Coach McGuirk' 10 54 2465 1414 59
'Coach McGuirk' 10 54 2479 1383 61
")
### Order factors by the order in data frame
### Otherwise, R will alphabetize them
Data$Instructor = factor(Data$Instructor,
levels=unique(Data$Instructor))
### Check the data frame
library(psych)
headTail(Data)
str(Data)
summary(Data)
Visualizing correlated variables
Correlation does not have independent and dependent variables
Notice in the formulae for the pairs and cor.test functions, that all variables are named to the right of the ~. One reason for this is that correlation is measured between two variables without assuming that one variable is the dependent variable and one is the independent variable. By necessity, one variable must be plotted on the x-axis and one on the y-axis, but their placement is arbitrary.
Multiple correlation
The pairs function can plot multiple numeric or integer variables on a single plot to look for correlations among the variables.
pairs(data=Data,
~ Grade + Weight + Calories + Sodium + Score)
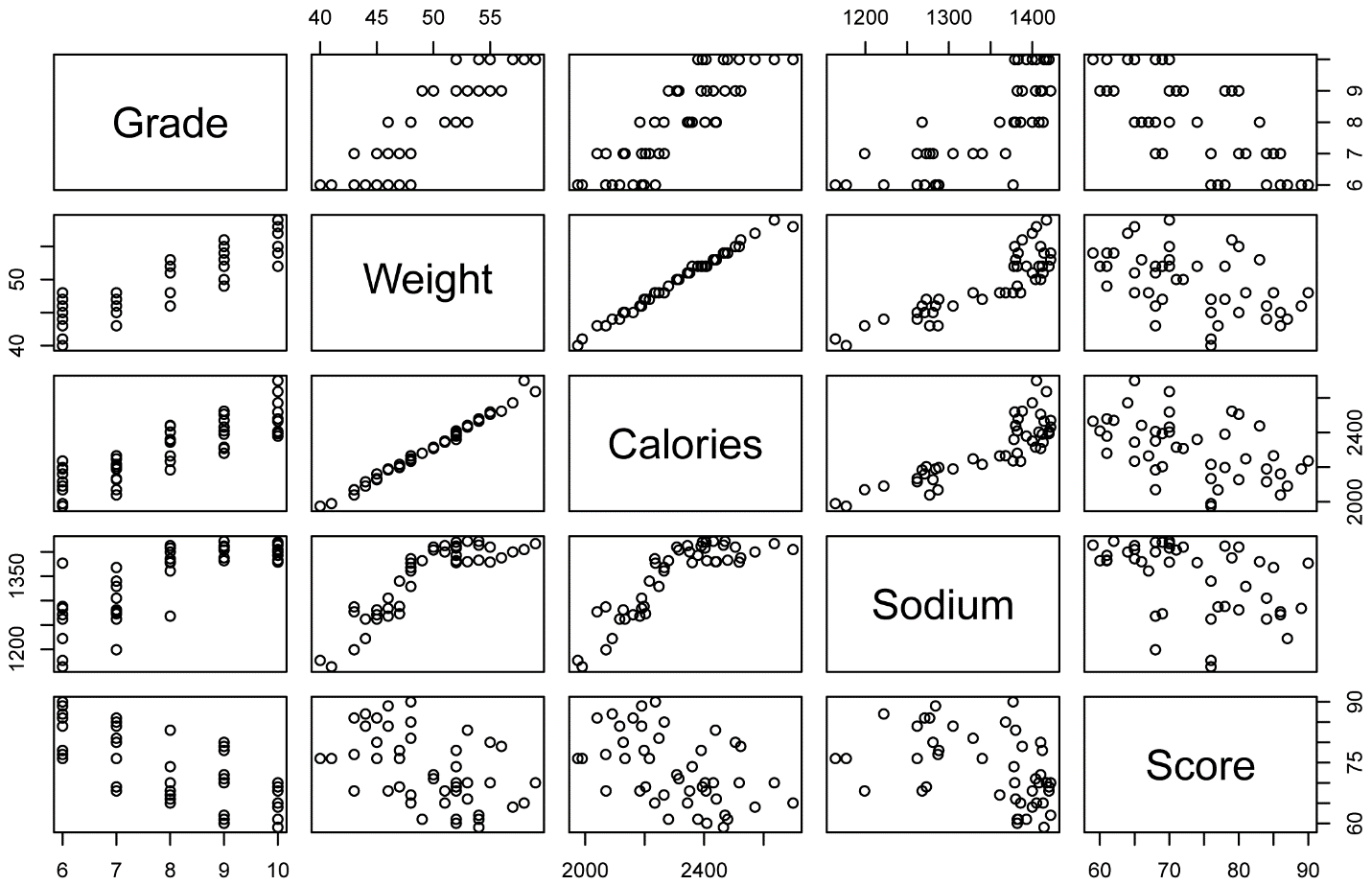
The corr.test function in the psych package can be used in a similar manner, with the output being a table of correlation coefficients and a table of p-values. p-values can be adjusted with the adjust= option. Options for correlation methods are “pearson”, “kendall”, and “spearman”. The function can produce confidence intervals for the correlation coefficients, but I recommend using the cor.ci function in the psych package for this task (not shown here).
The corr.test function requires that the data frame contain only numeric or integer variables, so we will first create a new data frame called Data.num containing only the numeric and integer variables.
Data.num = Data[c("Grade", "Weight", "Calories",
"Sodium", "Score")]
library(psych)
corr.test(Data.num,
use = "pairwise",
method = "pearson",
adjust = "none")
Correlation matrix
Grade Weight Calories Sodium Score
Grade 1.00 0.85 0.85 0.79 -0.70
Weight 0.85 1.00 0.99 0.87 -0.48
Calories 0.85 0.99 1.00 0.85 -0.48
Sodium 0.79 0.87 0.85 1.00 -0.45
Score -0.70 -0.48 -0.48 -0.45 1.00
Sample Size
[1] 45
A useful plot of histograms, correlations, and correlation coefficients can be produced with the chart.Correlation function in the PerformanceAnalytics package.
In the output, the numbers represent the correlation coefficients (r, tau, or rho, depending on whether Pearson, Kendall, or Spearman correlation is selected, respectively). The stars represent the p-value of the correlation:
* p < 0.05
** p < 0.01
*** p < 0.001
The function requires that the data frame contain only numeric or integer variables, so we will first create a new data frame called Data.num containing only the numeric and integer variables.
Data.num = Data[c("Grade", "Weight", "Calories",
"Sodium", "Score")]
library(PerformanceAnalytics)
chart.Correlation(Data.num,
method="pearson",
histogram=TRUE,
pch=16)

Effect size statistics
r, rho, and tau
The statistics r, rho, and tau are used as effect sizes for Pearson, Spearman, and Kendall regression, respectively. These statistics vary from –1 to 1, with 0 indicating no correlation, 1 indicating a perfect positive correlation, and –1 indicating a perfect negative correlation. Like other effect size statistics, these statistics are not affected by sample size.
Interpretation of effect sizes necessarily varies by discipline and the expectations of the experiment. They should not be considered universal. An interpretation of r is given by Cohen (1988). It is probably reasonable to use similar interpretations for rho and tau.
|
|
small
|
medium |
large |
|
r |
0.10 – < 0.30 |
0.30 – < 0.50 |
≥ 0.50 |
________________________________
Adapted from Cohen (1988).
r-squared
For linear regression, r-squared is used as an effect size statistic. It indicates the proportion of the variability in the dependent variable that is explained by model. That is, an r-squared of 0.60 indicates that 60% of the variability in the dependent variable is explained by the model.
Pearson correlation
The test used for Pearson correlation is a parametric analysis that requires that the relationship between the variables is linear, and that the data be bivariate normal. Variables should be interval/ratio. The test is sensitive to outliers.
The correlation coefficient, r, can range from +1 to –1, with +1 being a perfect positive correlation and –1 being a perfect negative correlation. An r of 0 represents no correlation whatsoever. The hypothesis test determines if the r value is significantly different from 0.
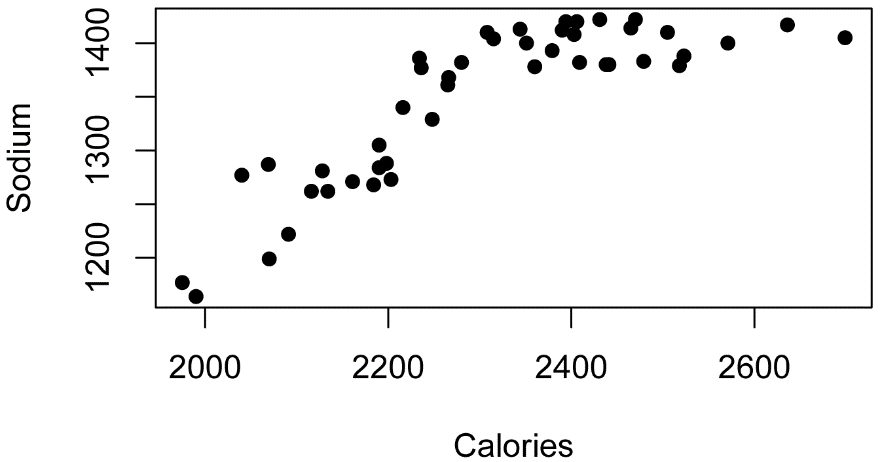
As an example, we’ll plot Sodium vs. Calories, and use the cor.test function to test the correlation of these two variables.
Simple plot of the data
Note that the relationship between the y and x variables is not particularly linear.
plot(Sodium ~ Calories,
data=Data,
pch=16,
xlab = "Calories",
ylab = "Sodium")
Pearson correlation
Note that the results report the p-value for the hypothesis test as well as the r value, written as cor, 0.849.
cor.test( ~ Sodium + Calories,
data=Data,
method = "pearson")
Pearson's product-moment correlation
t = 10.534, df = 43, p-value = 1.737e-13
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.7397691 0.9145785
sample estimates:
cor
0.8489548
An alternative method to obtain the confidence interval for r is to use a bootstrap method with the spearmanRho function with the method="pearson" option.
library(rcompanion)
spearmanRho( ~ Sodium + Calories,
data = Data,
method = "pearson",
ci = TRUE)
r lower.ci upper.ci
1 0.849 0.773 0.909
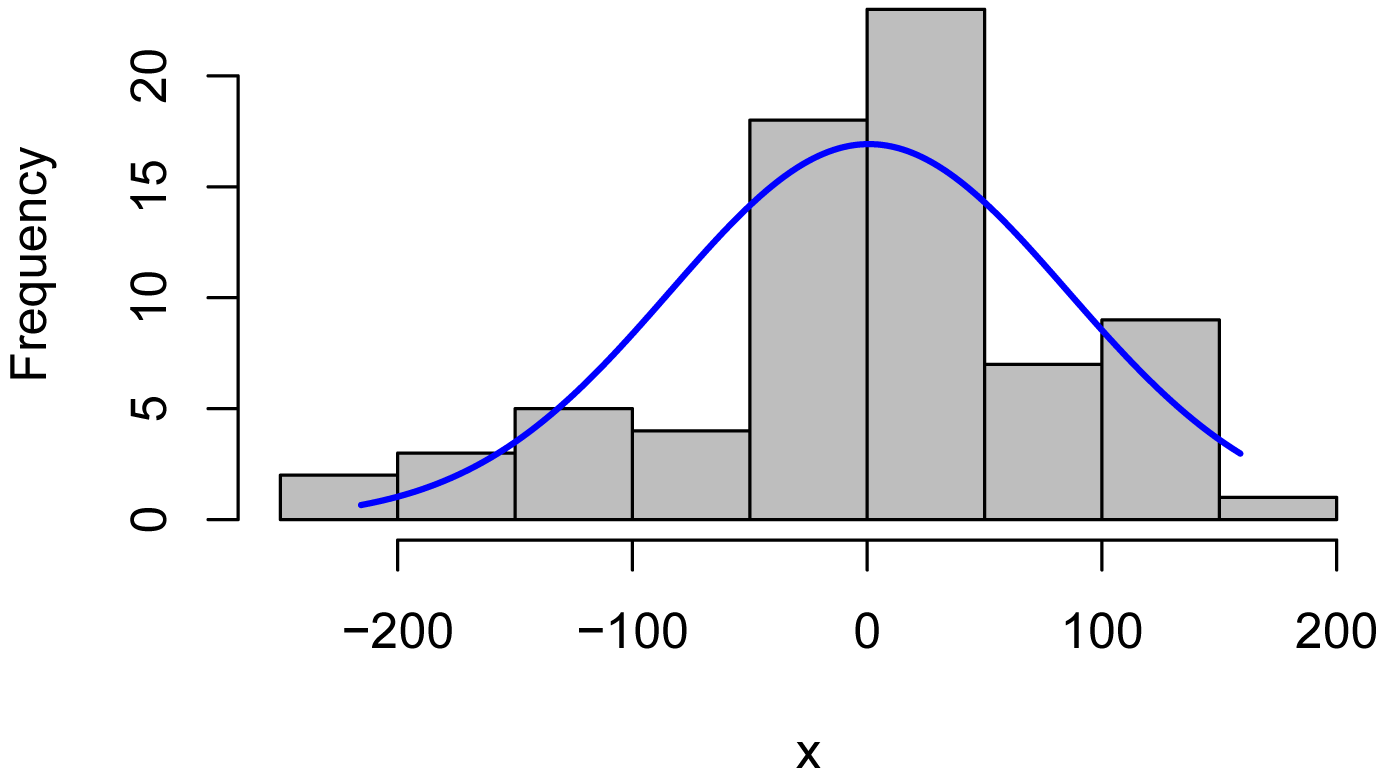
Plot residuals
It’s not a bad idea to look at the residuals from Pearson correlation to be sure the data meet the assumption of bivariate normality. Unfortunately, the cor.test function doesn’t supply residuals. One solution is to use the lm function, which actually redoes the analysis as a linear regression.
model = lm(Sodium ~ Calories,
data = Data)
x = residuals(model)
library(rcompanion)
plotNormalHistogram(x)
Kendall correlation
Kendall correlation is considered a nonparametric analysis. It is a rank-based test that does not require assumptions about the distribution of the data. Variables can be interval/ratio or ordinal.
The correlation coefficient from the test is tau, which can range from +1 to –1, with +1 being a perfect positive correlation and –1 being a perfect negative correlation. A tau of 0 represents no correlation whatsoever. The hypothesis test determines if the tau value is significantly different from 0.
As a technical note, the cor.test function in R calculates tau-b, which handles ties in ranks well.
The test is relatively robust to outliers in the data. The test is sometimes cited for being reliable when there are small number of samples or when there are many ties in ranks.
Simple plot of the data
(See Pearson correlation above.)
Kendall correlation
Note that the results report the p-value for the hypothesis test as well as the tau value, written as tau, 0.649.
cor.test( ~ Sodium + Calories,
data=Data,
method = "kendall")
Kendall's rank correlation tau
z = 6.2631, p-value = 3.774e-10
alternative hypothesis: true tau is not equal to 0
sample estimates:
tau
0.6490902
An estimate for tau with confidence interval by bootstrap can be obtained from the spearmanRho function with the method="kendall" option.
library(rcompanion)
spearmanRho( ~ Sodium + Calories,
data = Data,
method = "kendall",
ci = TRUE)
tau lower.ci upper.ci
1 0.649 0.495 0.768
Spearman correlation
Spearman correlation is considered a nonparametric analysis. It is a rank-based test that does not require assumptions about the distribution of the data. Variables can be interval/ratio or ordinal.
The correlation coefficient from the test, rho, can range from +1 to –1, with +1 being a perfect positive correlation and –1 being a perfect negative correlation. A rho of 0 represents no correlation whatsoever. The hypothesis test determines if the rho value is significantly different from 0.
Spearman correlation is probably most often used with ordinal data. It tests for a monotonic relationship between the variables. It is relatively robust to outliers in the data.
Simple plot of the data
(See Pearson correlation above.)
Spearman correlation
Note that the results report the p-value for the hypothesis test as well as the rho value, written as rho, 0.820.
cor.test( ~ Sodium + Calories,
data=Data,
method = "spearman")
Spearman's rank correlation rho
S = 2729.7, p-value = 5.443e-12
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.8201766
An estimate for rho with confidence interval can be obtained by running Pearson correlation on the ranks of the data. Note that the estimate of rho and the p-value are the same as for Spearman correlation.
cor.test( ~ rank(Sodium) + rank(Calories),
data = Data,
method = "pearson")
Pearson's product-moment correlation ON RANKS !!!
data: rank(Sodium) and rank(Calories)
t = 9.4007, df = 43, p-value = 5.443e-12
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.6936351 0.8976110
sample estimates:
cor
0.8201766
An estimate for rho with confidence interval by bootstrap can be obtained from the spearmanRho function with the method="spearman" option.
library(rcompanion)
spearmanRho( ~ Sodium + Calories,
data = Data,
method = "spearman",
ci = TRUE)
rho lower.ci upper.ci
1 0.82 0.644 0.906
Linear regression
Linear regression is a very common approach to model the relationship between two interval/ratio variables. The method assumes that there is a linear relationship between the dependent variable and the independent variable, and finds a best fit model for this relationship.
Dependent and Independent variables
When plotted, the dependent variable is usually placed on the y-axis, and the independent variable is usually placed in the x-axis.
Interpretation of coefficients
The outcome of linear regression includes estimating the intercept and the slope of the linear model. Linear regression can then be used as a predictive model, whereby the model can be used to predict a y value for any given x. In practice, the model shouldn’t be used to predict values beyond the range of the x values used to develop the model.
Multiple, nominal, and ordinal independent variables
If there are multiple independent variables of interval/ratio type in the model, then linear regression expands to multiple regression. The polynomial regression example in this chapter is a form of multiple regression.
If the independent variable were of nominal type, then the linear regression would become a one-way analysis of variance.
Handling independent variables of ordinal type can be complicated. Often they are treated as either nominal type or interval/ratio type, although there are drawbacks to each approach.
Assumptions
Linear regression assumes a linear relationship between the two variables, normality of the residuals, independence of the residuals, and homoscedasticity of residuals.
Note on writing r-squared
For bivariate linear regression, the r-squared value often uses a lower case r; however, some authors prefer to use a capital R. For multiple regression, the R in the R-squared value is usually capitalized. The name of the statistic may be written out as “r-squared” for convenience, or as r2.
Define model, and produce model coefficients, p-value, and r-squared value
Linear regression can be performed with the lm function, which was the same function we used for analysis of variance.
The summary function for lm model objects includes estimates for model parameters (intercept and slope), as well as an r-squared value for the model and p-value for the model.
Note that even for bivariate regression, the output calls the r-squared value “Multiple R-squared”.
model = lm(Sodium ~ Calories,
data = Data)
summary(model)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 519.07547 78.78211 6.589 5.09e-08 ***
Calories 0.35909 0.03409 10.534 1.74e-13 ***
Residual standard error: 38.89 on 43 degrees of freedom
Multiple R-squared: 0.7207, Adjusted R-squared: 0.7142
F-statistic: 111 on 1 and 43 DF, p-value: 1.737e-13
Plot data with best fit line
plot(Sodium ~ Calories,
data=Data,
pch=16,
xlab = "Calories",
ylab = "Sodium")
abline(model,
col = "blue",
lwd = 2)

There is a clear nonlinearity to the data, suggesting that the simple linear model is not the best fit. This nonlinearity is apparent in the plot of residuals vs. fitted values as well.
The next chapter will include fitting linear plateau, quadratic plateau, and a curvilinear models with this data.
The following section will attempt to improve the model fit by adding polynomial terms.
Plots of residuals
x = residuals(model)
library(rcompanion)
plotNormalHistogram(x)
plot(fitted(model),
residuals(model))

Polynomial regression
Polynomial regression adds additional terms to the model, so that the terms include some set of the linear, quadratic, cubic, and quartic, etc., forms of the independent variable. These terms are the independent variable, the square of the independent variable, the cube of the independent variable, and so on.
Create polynomial terms in the data frame
Because the variable Calories is an integer variable, we will need to convert it to a numeric variable. Otherwise R will produce errors when we try to square and cube the values of the variable.
Our new variables will be Calories2 for the square of Calories, Calories3 for the cube of Calories, and so on.
Data$Calories = as.numeric(Data$Calories)
Data$Calories2 = Data$Calories * Data$Calories
Data$Calories3 = Data$Calories * Data$Calories * Data$Calories
Data$Calories4 = Data$Calories * Data$Calories * Data$Calories * Data$Calories
Define models and determine best model
Chances are that we will not need all of the polynomial terms to adequately model our data. One approach to choosing the best model is to construct several models with increasing numbers of polynomial terms, and then use a model selection criterion like AIC, AICc, or BIC to choose the best one. These criteria balance the goodness-of-fit of each model versus its complexity. That is, the goal is to find a model which adequately explains the data without having too many terms.
We can use the compareLM function to list AIC, AICc, and BIC for a series of models.
model.1 = lm(Sodium ~ Calories,
data = Data)
model.2 = lm(Sodium ~ Calories + Calories2,
data = Data)
model.3 = lm(Sodium ~ Calories + Calories2 + Calories3,
data = Data)
model.4 = lm(Sodium ~ Calories + Calories2 + Calories3 + Calories4,
data = Data)
library(rcompanion)
compareLM(model.1, model.2, model.3, model.4)
$Models
Formula
1 "Sodium ~ Calories"
2 "Sodium ~ Calories + Calories2"
3 "Sodium ~ Calories + Calories2 + Calories3"
4 "Sodium ~ Calories + Calories2 + Calories3 + Calories4"
$Fit.criteria
Rank Df.res AIC AICc BIC R.squared Adj.R.sq p.value Shapiro.W
Shapiro.p
1 2 43 461.1 461.7 466.5 0.7207 0.7142 1.737e-13 0.9696
0.2800
2 3 42 431.4 432.4 438.6 0.8621 0.8556 8.487e-19 0.9791
0.5839
3 4 41 433.2 434.7 442.2 0.8627 0.8526 1.025e-17 0.9749
0.4288
4 5 40 428.5 430.8 439.4 0.8815 0.8696 5.566e-18 0.9625
0.1518
If we use BIC as our model fit criterion, we would choose model.2 as the best model for these data, since it had the lowest BIC. AIC or AICc could have been used as criteria instead.
BIC tends to penalize models more than the other criteria for having additional parameters, so it will tend to choose models with fewer terms.
There is not generally accepted advice as to which model fitting criterion to use. My advice might be to use BIC when a more parsimonious model (one with fewer terms) is a priority, and in other cases use AICc.
For final model, produce model coefficients, p-value, and R-squared value
summary(model.2)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.707e+03 6.463e+02 -5.736 9.53e-07 ***
Calories 4.034e+00 5.604e-01 7.198 7.58e-09 ***
Calories2 -7.946e-04 1.211e-04 -6.563 6.14e-08 ***
Residual standard error: 27.65 on 42 degrees of freedom
Multiple R-squared: 0.8621, Adjusted R-squared: 0.8556
F-statistic: 131.3 on 2 and 42 DF, p-value: < 2.2e-16
Note on retaining lower-order effects
In polynomial regression, we typically keep all lower order effects of any higher order effects we include. So, in this case, if the final model included Calories2, but the effect of Calories were not significant, we would still include Calories in the model since we are including Calories2.
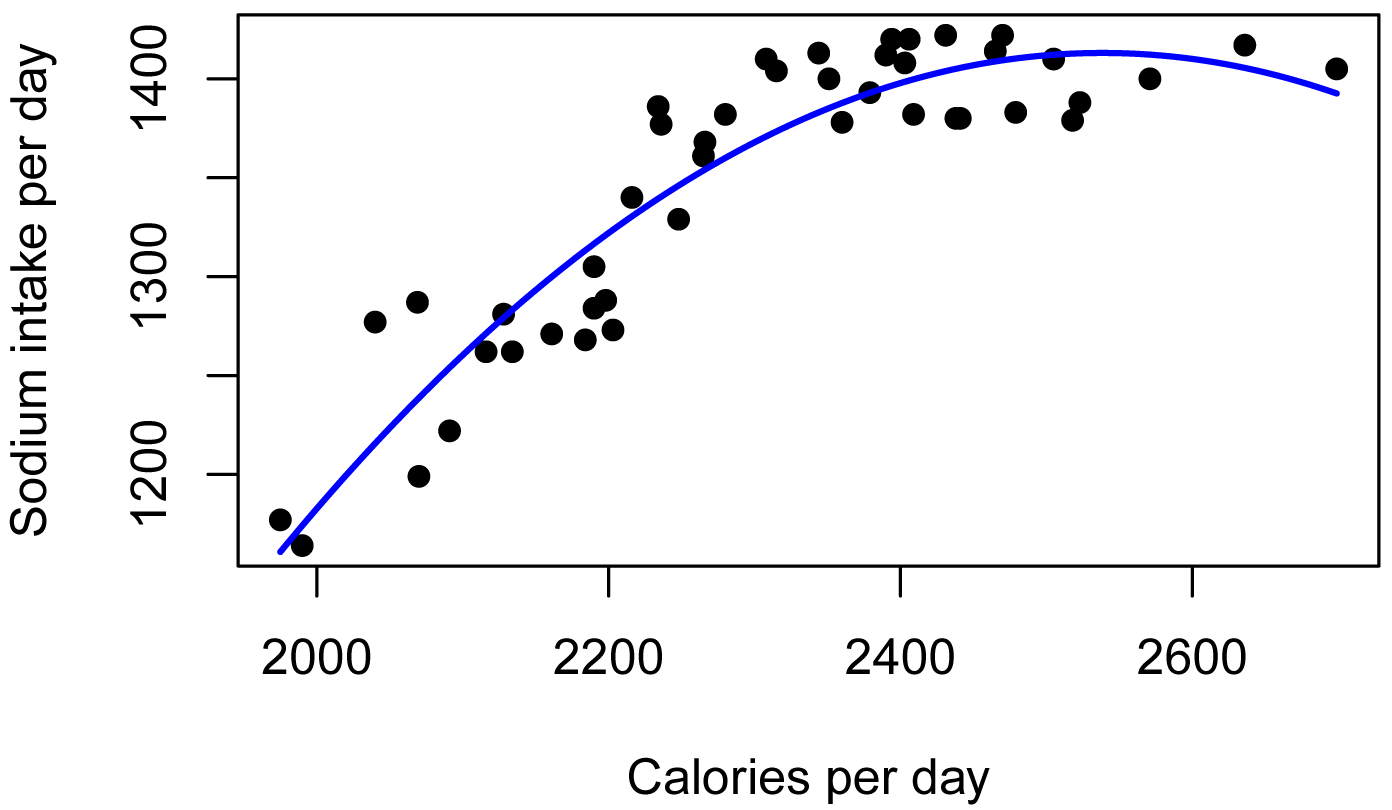
Plot data with best fit line
For bivariate data, the function plotPredy will plot the data and the predicted line for the model. It also works for polynomial functions, if the order option is changed.
library(rcompanion)
plotPredy(data = Data,
y = Sodium,
x = Calories,
x2 = Calories2,
model = model.2,
order = 2,
xlab = "Calories per day",
ylab = "Sodium intake per day")
Plot of best fit line with confidence interval
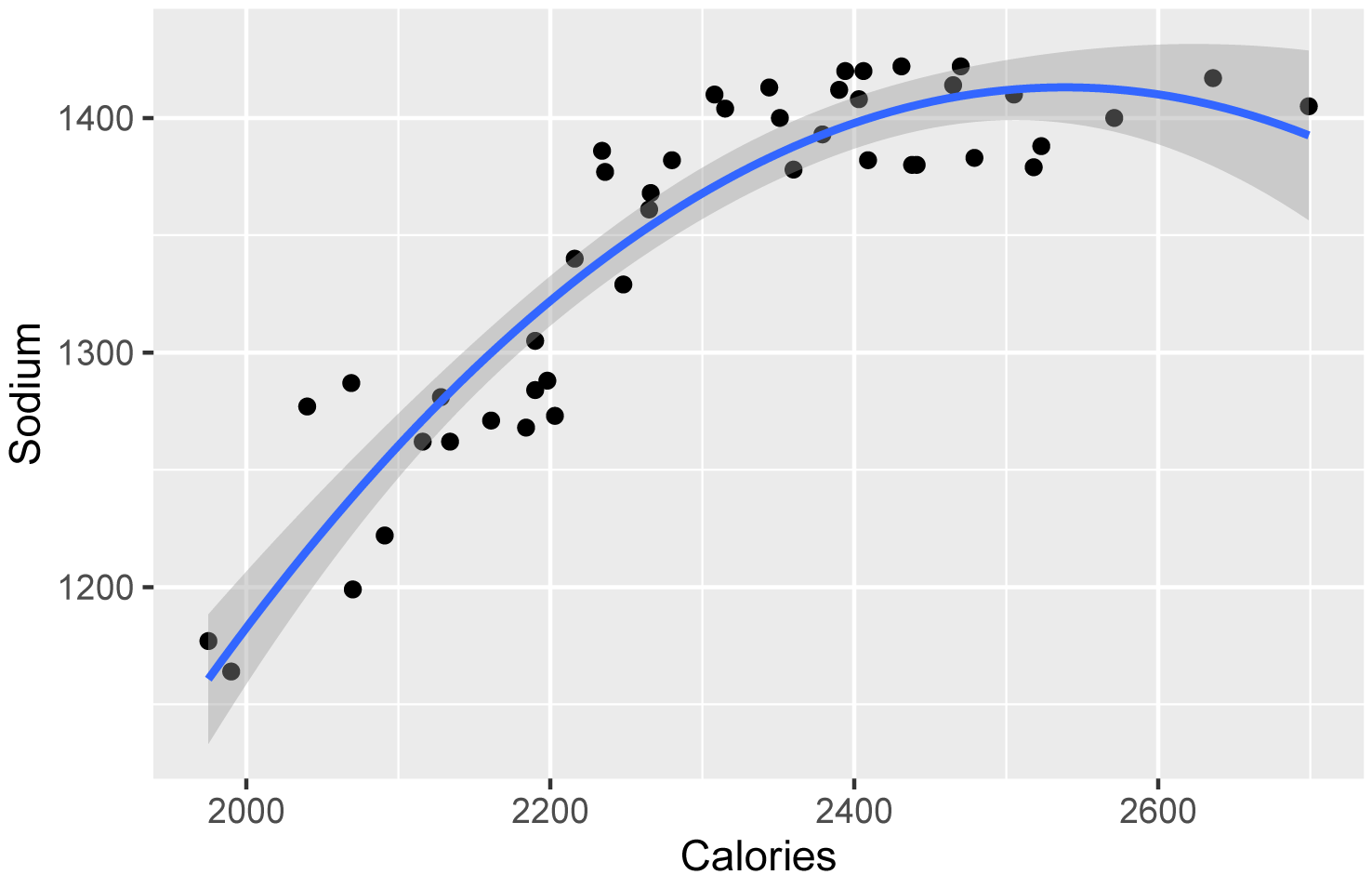
For polynomial regression, the ggplot function can plot the best-fit curve with the confidence interval of the curve shaded.
library(ggplot2)
ggplot(Data,
aes(x = Calories,
y = Sodium)) +
geom_point() +
geom_smooth(method = "lm",
formula = y ~ poly(x, 2, raw=TRUE), ###
polynomial of order 2
se = TRUE)
Plots of residuals
x = residuals(model.2)
library(rcompanion)
plotNormalHistogram(x)

plot(fitted(model.2),
residuals(model.2))

A few of xkcd comics
Correlation
Extrapolating
Cat proximity
References
Cohen, J. 1988. Statistical Power Analysis for the Behavioral Sciences, 2nd Edition. Routledge.
“Correlation and Linear Regression” in Mangiafico, S.S. 2015. An R Companion for the Handbook of Biological Statistics. rcompanion.org/rcompanion/e_01.html.
“Multiple Regression” in Mangiafico, S.S. 2015. An R Companion for the Handbook of Biological Statistics. rcompanion.org/rcompanion/e_05.html.
Exercises U
1. Consider the data from Brendon, Jason, Melissa, Paula,
and McGuirk. Report for each answer, indicate how you know, when
appropriate, by reporting the values of the statistic you are using or other
information you used.
a. Which two variables are the most strongly correlated?
b. Which two variables are the least strongly correlated?
c. Are there any pairs of variables that are statistically uncorrelated?
Which?
d. Name a pair of variables that is positively correlated.
e. Name a pair of variables that is negatively correlated.
f. Is Sodium significantly correlated with Calories?
g. By linear regression, is there a significant linear
relationship of Sodium vs. Calories?
h. Does the quadratic polynomial model fit the Sodium vs. Calories data better than the linear model? Consider the p-value, the r-squared value, the range of values for each of Sodium and Calories, and your practical conclusions.
2. As part of a professional skills program, a 4-H club tests its members for
typing proficiency (Words.per.minute), Proofreading skill,
proficiency with using a Spreadsheet, and acumen in Statistics.
Instructor Grade Words.per.minute Proofreading Spreadsheet Statistics
'Dr. Katz' 6 35 53 75 61
'Dr. Katz' 6 50 77 24 51
'Dr. Katz' 6 55 71 62 55
'Dr. Katz' 6 60 78 27 91
'Dr. Katz' 6 65 84 44 95
'Dr. Katz' 6 60 79 38 50
'Dr. Katz' 6 70 96 12 94
'Dr. Katz' 6 55 61 55 76
'Dr. Katz' 6 45 73 59 75
'Dr. Katz' 6 55 75 55 80
'Dr. Katz' 6 60 85 35 84
'Dr. Katz' 6 45 61 49 80
'Laura' 7 55 59
79 57
'Laura' 7 60 60 60 60
'Laura' 7 75 90 19 64
'Laura' 7 65 87 32 65
'Laura' 7 60 70 33 94
'Laura' 7 70 84 27 54
'Laura' 7 75 87 24 59
'Laura' 7 70 97 38 74
'Laura' 7 65 86 30 52
'Laura' 7 72 91 36 66
'Laura' 7 73
88 20 57
'Laura' 7 65 86 19 71
'Ben Katz' 8 55 84 20 76
'Ben Katz' 8 55 63 44 94
'Ben Katz' 8 70 95 31 88
'Ben Katz' 8 55 63 69 93
'Ben Katz' 8 65 65 47 70
'Ben Katz' 8 60 61 63 92
'Ben Katz' 8 70 80 35 60
'Ben Katz' 8 60 88 38 58
'Ben Katz' 8 60 71 65 99
'Ben Katz' 8 62 78 46 54
'Ben Katz' 8 63 89 17 60
'Ben Katz' 8 65 75 33 77
For each of the following, answer the question, and show the output from the analyses you used to answer the question. Where relevant, indicate how you know.
a. Which two variables are the most strongly correlated?
b. Name a pair of variables that are statistically uncorrelated.
c. Name a pair of variables that is positively correlated.
d. Name a pair of variables that is negatively correlated.
e. Consider the correlation between Spreadsheet and Proofreading.
i. What is the value of the correlation coefficient r for this correlation?
ii. What is the value of tau?
iii. What is the value of rho?
f. Conduct a linear regression of Proofreading vs. Words.per.minute.
i. What is the p-value for this model?
ii. What is the r-squared value?
iii. Do the residuals suggest that the linear regression model is an appropriate model?
iv. What can you conclude about the results of the linear
regression? Consider the p-value, the r-squared value, the range
of values for each of Proofreading and Words.per.minute, and your
practical conclusions.