![[banner]](images/banner.jpg "Cohansey River, Fairfield, New Jersey")
The two-sample signed-rank test for paired data is used to compare values for two groups where each observation in one group is paired with one observation in the other group.
The test is useful to compare scores on a pre-test vs. scores on a post-test, or scores or ratings from two speakers, two different presentations, or two groups of audiences when there is a reason to pair observations, such as being done by the same rater.
A discussion of paired data can be found in the Independent and Paired Values chapter of this book.
Because the first step in the calculations is the subtraction of the paired values, one from the other, the data must be at least ordinal in nature.
The test is equivalent to using a one-sample signed-rank test on the difference of the paired values.
In base R, the test is performed with the wilcox.test function with the paired=TRUE option. However, the wilcoxsign_test in the coin package has the advantage of using the Pratt method to handle zero differences, which may be preferable in some cases.
Appropriate data
• Two-sample paired data. That is, one-way data with two groups only, where the observations are paired between groups.
• Dependent variable is interval, or ratio
• Independent variable is a factor with two levels. That is, two groups
• For the test to be a test of the median of the differences, the distribution of differences in paired samples needs to be symmetric
Hypotheses
• Null hypothesis: The population of the differences of paired values is symmetric around zero.
• Alternate hypothesis: (two-sided): The population of the differences of paired values is not symmetric around zero.
Interpretation
Significant results can be reported as e.g. “Values for group A were significantly different from those of group B.”
Other notes and alternative tests
Some authors recommend this test only in cases where the distribution of the differences is symmetric. It is my understanding that this requirement is only for the test to be considered a test of the median of the differences. For a little more discussion on this point, see the One-sample Wilcoxon Signed-rank Test chapter.
If the median is the statistic of interest, the two-sample sign test for paired data can be used.
Packages used in this chapter
The packages used in this chapter include:
• psych
• coin
• rcompanion
• exactRankTests
The following commands will install these packages if they are not already installed:
if(!require(psych)){install.packages("psych")}
if(!require(coin)){install.packages("coin")}
if(!require(rcompanion)){install.packages("rcompanion")}
if(!require(exactRankTests)){install.packages("exactRankTests")}
Two-sample paired signed-rank test example
For this example, imagine we want to compare scores for Pooh between Time 1 and Time 2. Here, we’ve recorded the identity of the student raters, and Pooh’s score for each rater. This allows us to focus on the changes for each rater between Time 1 and Time 2. This makes for a more powerful test than would the Mann–Whitney U test in cases like this where one rater might tend to rate high and another rater might tend to rate low, but there is an overall trend in how raters change their scores between Time 1 and Time 2.
Note in this example we needed to record the identity of the student rater so that a rater’s score from Time 1 can be paired with their score from Time 2. If we cannot pair data in this way—for example, if we did not record the identity of the raters—the data would have to be treated as unpaired, independent samples, for example like those in the Two-sample Mann–Whitney U Test chapter.
Also note that the data is arranged in long form. In this form, for this test, the data must be ordered so that the first observation where Time = 1 is paired to the first observation where Time = 2, and so on.
Data = read.table(header=TRUE, stringsAsFactors=TRUE, text="
Speaker Time Student Likert
Pooh 1 a 1
Pooh 1 b 4
Pooh 1 c 3
Pooh 1 d 3
Pooh 1 e 3
Pooh 1 f 3
Pooh 1 g 4
Pooh 1 h 3
Pooh 1 i 3
Pooh 1 j 3
Pooh 2 a 4
Pooh 2 b 5
Pooh 2 c 4
Pooh 2 d 5
Pooh 2 e 4
Pooh 2 f 5
Pooh 2 g 3
Pooh 2 h 4
Pooh 2 i 3
Pooh 2 j 4
")
### Order data by Time and Student if not already ordered
Data = Data[order(Data$Time, Data$Student),]
### Check the data frame
library(psych)
headTail(Data)
str(Data)
summary(Data)
Number of observations per group
It is helpful to check the data to be sure there is one observation per student per time.
xtabs( ~ Student + Time,
data = Data)
Time
Student 1 2
a 1 1
b 1 1
c 1 1
d 1 1
e 1 1
f 1 1
g 1 1
h 1 1
i 1 1
j 1 1
Plot the paired data
Scatter plot with one-to-one line
Paired data can be visualized with a scatter plot of the paired cases. In the plot below, points that fall above and to the left of the blue line indicate cases for which the value for Time 2 was greater than for Time 1.
Note that the points in the plot are jittered slightly so that points which would fall directly on top of one another can be seen.
First, two new variables, Time.1 and Time.2, are created by extracting the values of Likert for observations with the Time variable equal to 1 or 2, respectively, and then the plot is produced.
Note that for this to work correctly, the data must be ordered so that the first observation where Time = 1 is paired to the first observation where Time = 2, and so on.
Time.1 = Data$Likert[Data$Time==1]
Time.2 = Data$Likert[Data$Time==2]
plot(Time.1, jitter(Time.2), # jitter offsets
points so you can see them all
pch = 16, # shape of points
cex = 1.0, # size of points
xlim=c(1, 5.5), # limits of x axis
ylim=c(1, 5.5), # limits of y axis
xlab="Time 1",
ylab="Time 2"
)
abline(0,1, col="blue", lwd=2) # line
with intercept of 0 and slope of 1

Bar plot of differences
Paired data can also be visualized with a bar chart of differences. In the plot below, bars with a value greater than zero indicate cases for which values for Time 2 are greater than for Time 1.
New variables are first created for Time.1, Time.2, and their Difference. And then the plot is produced.
Note that for this to work correctly, the data must be ordered so that the first observation where Time = 1 is paired to the first observation where Time = 2, and so on.
Time.1 = Data$Likert[Data$Time==1]
Time.2 = Data$Likert[Data$Time==2]
Difference = Time.2 - Time.1
barplot(Difference, #
variable to plot
col="dark gray", # color of bars
xlab="Observation", # x-axis label
ylab="Difference (Time 2 – Time 1)") # y-axis label

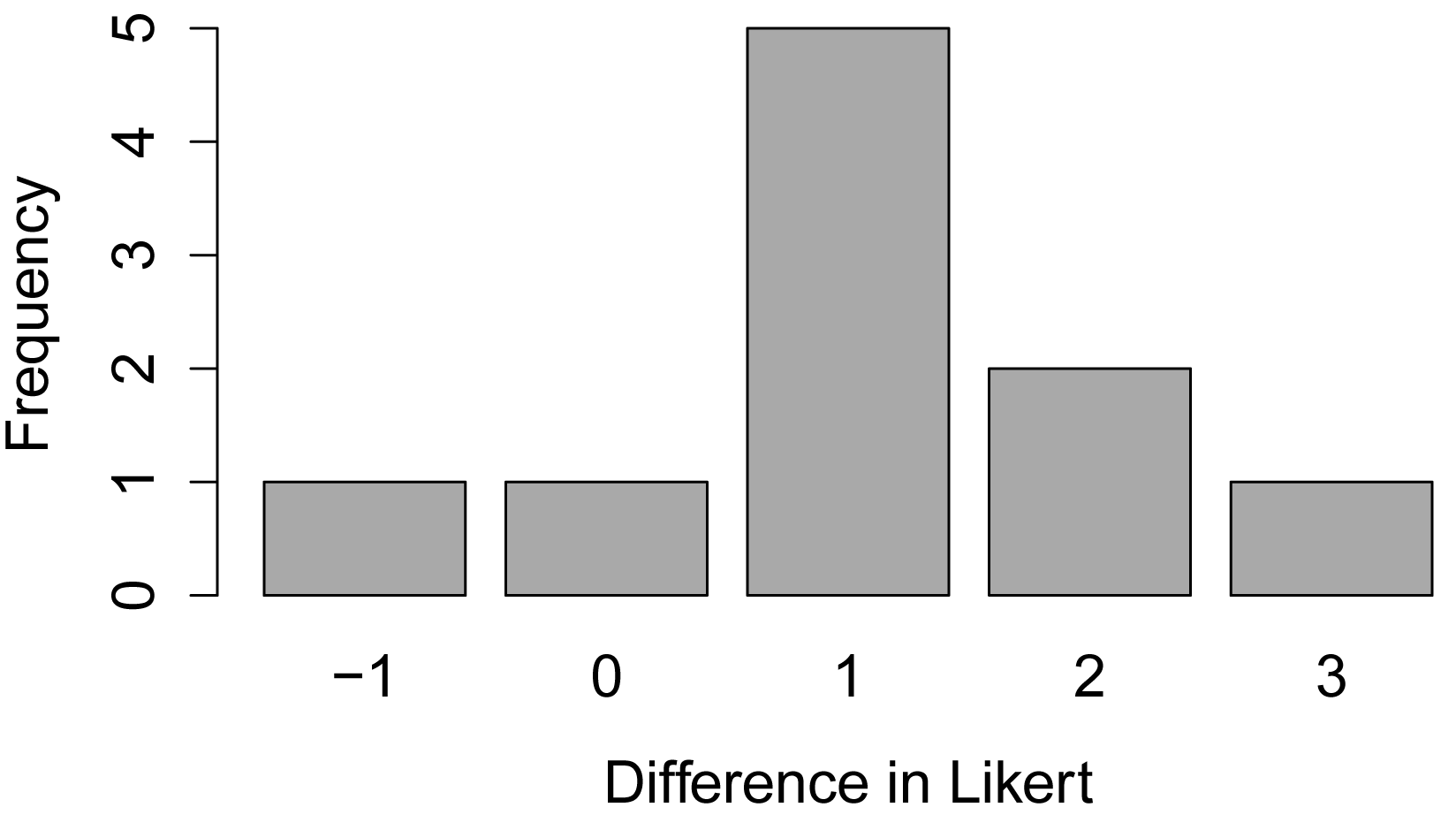
Bar plot of differences
A bar plot of differences in paired data can be used to examine the distribution of the differences.
Here, new variables are created: Time.1, Time.2, Difference, and Diff.f, which has the same values as Difference but as a factor variable. The xtabs function is used to create a count of values of Diff.f. The barplot function then uses these counts.
Note that for this to work correctly, the data must be ordered so that the first observation where Time = 1 is paired to the first observation where Time = 2, and so on.
Time.1 = Data$Likert[Data$Time==1]
Time.2 = Data$Likert[Data$Time==2]
Difference = Time.2 - Time.1
Diff.f = factor(Difference)
XT = xtabs(~ Diff.f)
barplot(XT,
col="dark gray",
xlab="Difference in Likert",
ylab="Frequency")
Descriptive statistics
It is helpful to look at medians for each group and the median difference between groups in order to determine the practical importance of the differences.
library(FSA)
Summarize(Likert ~ Time,
data = Data)
Time n mean sd min Q1 median Q3 max
1 1 10 3.0 0.8164966 1 3 3 3.00 4
2 2 10 4.1 0.7378648 3 4 4 4.75 5
Note that for the following to work correctly, the data must be ordered so that the first observation where Time = 1 is paired to the first observation where Time = 2, and so on.
Time.1 = Data$Likert[Data$Time==1]
Time.2 = Data$Likert[Data$Time==2]
Difference = Time.2 - Time.1
median(Difference)
[1] 1
Two-sample paired signed-rank test
R no longer allows for the use of formula notation with the paired samples wilcox.test function.
So, this example creates new variables for the observations for each Time period.
The option paired=TRUE indicates that the test for paired data should be used. For the meaning of other options, see ?wilcox.test.
Time.1 = Data$Likert[Data$Time==1]
Time.2 = Data$Likert[Data$Time==2]
wilcox.test(Time.1, Time.2,
paired = TRUE,
conf.int = TRUE,
conf.level = 0.95)
Wilcoxon signed rank test with continuity correction
V = 3.5, p-value = 0.02355
alternative hypothesis: true location shift is not equal to 0
### Note the p-value given in the above results
95 percent confidence interval:
-2.000051e+00 -1.458002e-05
### Confidence interval for the location of differences
### You may get a "cannot compute exact p-value
with ties" error.
### You can ignore this or use the exact=FALSE option.
Coin package
By default, the wilcoxsign_test function uses the Pratt method to handle zero differences.
library(coin)
Time.1 = Data$Likert[Data$Time==1]
Time.2 = Data$Likert[Data$Time==2]
wilcoxsign_test(Time.1 ~ Time.2)
Asymptotic Wilcoxon-Pratt Signed-Rank Test
Z = -2.3522, p-value = 0.01866
alternative hypothesis: true mu is not equal to 0
exactRankTests package
library(exactRankTests)
wilcox.exact(Likert ~ Time,
data = Data,
paired = TRUE,
exact = TRUE,
conf.int = TRUE,
conf.level = 0.95)
Exact Wilcoxon signed rank test
V = 3.5, p-value = 0.02734
95 percent confidence interval:
-2.5 -0.5
sample estimates:
(pseudo)median
-1.25
Effect size
The matched-pairs rank biserial correlation coefficient (rc) is a recommended effect size statistic. It is included in King, Rosopa, and Minimum (2000).
As an alternative, using a statistic analogous to the r used in the Mann–Whitney test may make sense.
The following interpretation is based on my personal intuition. It is not intended to be universal.
|
|
small
|
medium |
large |
|
rc |
0.10 – < 0.30 |
0.30 – < 0.50 |
≥ 0.50 |
|
r |
0.10 – < 0.40 |
0.40 – < 0.60 |
≥ 0.60 |
rc
library(rcompanion)
wilcoxonPairedRC(x = Data$Likert,
g = Data$Time)
rc
-0.844
### Note that a negative rc value indicates that the
second group tends to have
### larger values than the first group.
wilcoxonPairedRC(x = Data$Likert, g = Data$Time, ci=TRUE)
rc lower.ci upper.ci
-0.844 -1 -0.418
### Note that the confidence interval endpoints may
vary.
r
library(rcompanion)
wilcoxonPairedR(x = Data$Likert,
g = Data$Time)
r
-0.737
### Note that a negative r value indicates that the
second group tends to have
### larger values than the first group.
wilcoxonPairedR(x = Data$Likert, g = Data$Time, ci=TRUE)
r lower.ci upper.ci
-0.737 -0.939 -0.364
### Note that the confidence interval endpoints may
vary.
References
King, B.M., P.J. Rosopa, E.W. and Minium. 2000. Statistical Reasoning in the Behavioral Sciences, 6th. Wiley.
Exercises K
1. Considering Pooh’s data for Time 1 and Time 2,
a. What do the plots suggest about the relative value of the
scores for Time 1 and Time 2? That is, do they suggest that scores increased,
decreased, or stayed the same between Time 1 and Time 2?
b. Is the distribution of the differences between paired
samples relatively symmetrical?
c. Does the two-sample paired signed-rank test indicate that
there is a significant difference between Time 1 and Time 2?
d. Practically speaking, what do you conclude? If significant, is the difference between Time 1 and Time 2 of practical importance?
2. Lois Griffin gave proficiency scores to her students in her course on piano
playing for adults. She gave a score for each student for their left hand
playing and right hand playing. She wants to know if students in her class are
more proficient in the right hand, left hand, or if there is no difference in
hands.
Instructor Student Hand Score
'Lois Griffin' a left 8
'Lois Griffin' a right 9
'Lois Griffin' b left 6
'Lois Griffin' b right 5
'Lois Griffin' c left 7
'Lois Griffin' c right 9
'Lois Griffin' d left 6
'Lois Griffin' d right 7
'Lois Griffin' e left 7
'Lois Griffin' e right 7
'Lois Griffin' f left 9
'Lois Griffin' f right 9
'Lois Griffin' g left 4
'Lois Griffin' g right 6
'Lois Griffin' h left 5
'Lois Griffin' h right 8
'Lois Griffin' i left 5
'Lois Griffin' i right 6
'Lois Griffin' j left 7
'Lois Griffin' j right 8
For each of the following, answer the question, and show the output from the analyses you used to answer the question.
a. Is the distribution of the differences between paired samples relatively symmetrical?
b. Does the two-sample paired signed-rank test indicate that
there is a difference between hands? If so, which hand received higher scores?
c. What can you conclude about the results of the plots, summary statistics, effect size, and statistical test? Practically speaking, what do you conclude? If significant, is the difference between hands of practical importance?
d. What if Lois wanted to change the design of the experiment so that she could determine if each student were more proficient in one hand or the other? That is, is student a more proficient in left hand or right? Is student b more proficient in left hand or right? How should she change what data she’s collecting to determine this?