![[banner]](images/banner.jpg "Cohansey River, Fairfield, New Jersey")
When developing more complex models, it is often desirable to report a p-value for the model as a whole as well as an R-square for the model.
p-values for models
The p-value for a model determines the significance of the model compared with a null model. For a linear model, the null model is defined as the dependent variable being equal to its mean. So, the p-value for the model is answering the question, Does this model explain the values of the dependent variable significantly better than would just looking at the average value of the dependent variable?
R-squared and pseudo R-squared
The R-squared value is a measure of how well the model explains the data. It is an example of a goodness-of-fit statistic.
R-squared for linear (ordinary least squares) models
In R, models fit with the lm function are linear models fit with ordinary least squares (OLS). For these models, R-squared indicates the proportion of the variability in the dependent variable that is explained by model. That is, an R-squared of 0.60 indicates that 60% of the variability in the dependent variable is explained by the model.
Pseudo R-squared
For many types of models, R-squared is not defined. These include relatively common models like logistic regression and the cumulative link models used in this book. For these models, pseudo R-squared measures can be calculated. A pseudo R-squared is not directly comparable to the R-squared for OLS models. Nor can it be interpreted as the proportion of the variability in the dependent variable that is explained by model. Instead, pseudo R-squared measures are relative measures among similar models indicating how well the model explains the data.
A few common pseudo R-squared measures include: McFadden, Cox and Snell (also referred to as ML), Nagelkerke (also referred to as Cragg and Uhler), Efron, and count.
Some pseudo R-squared measures work better with some types of models. It takes some experience or research to determine which may work best in a given situation. McFadden, Cox and Snell, and Nagelkerke are based on the likelihood estimates of the model. Nagelkerke is the same as the Cox and Snell, except that the value is adjusted upward so that the Nagelkerke has a maximum value of 1. Efron’s pseudo R-squared has the advantage of being based solely on the actual values of the dependent variable and those values predicted by the model. This makes it relatively easy to understand. The count pseudo R-squared is used in cases of a binary predicted value, and simply compares the number of correct responses to the total number of responses.
p-values and R-squared values.
p-values and R-squared values measure different things. The p-value indicates if there is a significant relationship described by the model. Essentially, if there is enough evidence that the model explains the data better than would a null model. The R-squared measures the degree to which the data is explained by the model. It is therefore possible to get a significant p-value with a low R-squared value. This often happens when there are enough data points to supply sufficient evidence that the model is better than the null model (significant p-value), but variability in the dependent variable isn’t explained too well by the model (low R-squared).
Packages used in this chapter
The packages used in this chapter include:
• psych
• lmtest
• boot
• rcompanion
The following commands will install these packages if they are not already installed:
if(!require(psych)){install.packages("psych")}
if(!require(lmtest)){install.packages("lmtest")}
if(!require(boot)){install.packages("boot")}
if(!require(rcompanion)){install.packages("rcompanion")}
Example of model p-value, R-squared, and pseudo R-squared
The following example uses some hypothetical data of a sample of people for which typing speed (Words.per.minute) and age were measured. After plotting the data, we decide to construct a polynomial model with Words.per.minute as the dependent variable and Age and Age2 as the independent variables. Notice in this example that all variables are treated as interval/ratio variables, and that the independent variables are also continuous variables.
The data will first be fit with a linear model with the lm function. Passing this model to the summary function will display the p-value for the model and the R-squared value for the model.
The same data will then be fit with a generalized linear model with the glm function. This type of model allows more latitude in the types of data that can be fit, but in this example, we’ll use the family=gaussian option, which will mimic the model fit with the lm function, though the underlying math is different.
Importantly, the summary of the glm function does not produce a p-value for the model nor an R-squared for the model.
For the model fit with glm, the p-value can be determined with the anova function comparing the fitted model to a null model. The null model is fit with only an intercept term on the right side of the model. As an alternative, the nagelkerke function described below also reports a p-value for the model, using the likelihood ratio test.
There is no R-squared defined for a glm model. Instead, a pseudo R-squared can be calculated. The function nagelkerke produces pseudo R-squared values for a variety of models. It reports three types: McFadden, Cox and Snell, and Nagelkerke. The efronRSquared function reports Efron’s pseudo R-squared for a variety of models.
Note that these models make certain assumptions about the distribution of the underlying population data, but for simplicity, this example will ignore the need to determine if these assumptions are met.
Data = read.table(header=TRUE, stringsAsFactors=TRUE, text="
Age Words.per.minute
12 23
12 32
12 25
13 27
13 30
15 29
15 33
16 37
18 29
22 33
23 37
24 33
25 43
27 35
33 30
42 25
53 22
")
### Check the data frame
library(psych)
headTail(Data)
str(Data)
summary(Data)
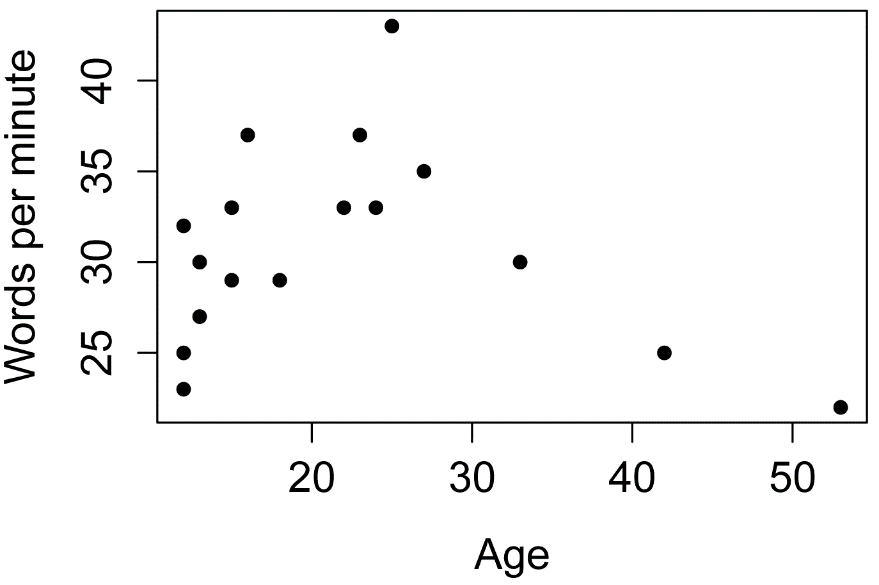
Plot the data
plot(Words.per.minute ~ Age,
data = Data,
pch=16,
xlab = "Age",
ylab = "Words per minute")
Prepare data
### Create new variable for the square of Age
Data$Age2 = Data$Age ^ 2
### Double check data frame
library(psych)
headTail(Data)
Age Words.per.minute Age2
1 12 23 144
2 12 32 144
3 12 25 144
4 13 27 169
... ... ... ...
14 27 35 729
15 33 30 1089
16 42 25 1764
17 53 22 2809
Linear model
model = lm (Words.per.minute ~ Age + Age2,
data=Data)
summary(model) ### Shows coefficients,
### p-value for model, and
R-squared
Multiple R-squared: 0.5009, Adjusted R-squared: 0.4296
F-statistic: 7.026 on 2 and 14 DF, p-value: 0.00771
### p-value and (multiple) R-squared value
Simple plot of data and model
For bivariate data, the function plotPredy will plot the data and the predicted line for the model. It also works for polynomial functions, if the order option is changed.
library(rcompanion)
plotPredy(data = Data,
y = Words.per.minute,
x = Age,
x2 = Age2,
model = model,
order = 2,
xlab = "Words per minute",
ylab = "Age")

Generalized linear model
model = glm (Words.per.minute ~ Age + Age2,
data = Data,
family = gaussian)
summary(model) ### Shows coefficients
Calculate p-value for model
In R, the most common way to calculate the p-value for a fitted model is to compare the fitted model to a null model with the anova function. The null model is usually formulated with just a constant on the right side.
null = glm (Words.per.minute ~ 1, ### Create
null model
data = Data, ### with
only a constant on the right side
family = gaussian)
anova(model,
null,
test="Chisq") ###
Tests options "Rao", "LRT",
### "Chisq", "F",
"Cp"
### But some work with only some model
types
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 14 243.07
2 16 487.06 -2 -243.99 0.0008882 ***
Calculate pseudo R-squared and p-value for model
An alternative test for the p-value for a fitted model, the nagelkerke function will report the p-value for a model using the likelihood ratio test.
The nagelkerke function also reports the McFadden, Cox and Snell, and Nagelkerke pseudo R-squared values for the model.
library(rcompanion)
nagelkerke(model)
$Pseudo.R.squared.for.model.vs.null
Pseudo.R.squared
McFadden 0.112227
Cox and Snell (ML) 0.500939
Nagelkerke (Cragg and Uhler) 0.501964
$Likelihood.ratio.test
Df.diff LogLik.diff Chisq p.value
-2 -5.9077 11.815 0.0027184
We can obtain Efron’s pseudo R-squared from the efronRsquared function or the accuracy function.
The accuracy function also outputs several other measures of accuracy and error.
efronRSquared(model)
EfronRSquared
0.501
accuracy(model)
$Fit.criteria
Min.max.accuracy MAE MedAE MAPE MSE RMSE NRMSE.mean NRMSE.median
Efron.r.squared CV.prcnt
1 0.902 3.19 2.92 0.106 14.3 3.78 0.123 0.126
0.501 12.3
Likelihood ratio test for p-value for model
The p-value for a model by the likelihood ratio test can also be determined with the lrtest function in the lmtest package.
library(lmtest)
lrtest(model)
#Df LogLik Df Chisq Pr(>Chisq)
1 4 -46.733
2 2 -52.641 -2 11.815 0.002718 **
Simple plot of data and model
library(rcompanion)
plotPredy(data = Data,
y = Words.per.minute,
x = Age,
x2 = Age2,
model = model,
order = 2,
xlab = "Words per minute",
ylab = "Age",
col = "red") ###
line color

Optional analyses: Confidence intervals for R-squared values
It is relatively easy to produce confidence intervals for R-squared values or other parameters from model fitting, such as coefficients for regression terms. This can be accomplished with bootstrapping. Here the boot.ci function from the boot package is used.
The code below is a little complicated, but relatively flexible.
Function can contain any function of interest, as long as it includes an input vector or data frame (input in this case) and an indexing variable (index in this case). Stat is set to produce the actual statistic of interest on which to perform the bootstrap (r.squared from the summary of the lm in this case).
The code Function(Data, 1:n) is there simply to test Function on the data frame Data. In this case, it will produce the output of Function for the first n rows of Data. Since n is defined as the length of the first column in Data, this should return the value for Stat for the whole data frame, if Function is set up correctly.
Data = read.table(header=TRUE, stringsAsFactors=TRUE, text="
Age Words.per.minute
12 23
12 32
12 25
13 27
13 30
15 29
15 33
16 37
18 29
22 33
23 37
24 33
25 43
27 35
33 30
42 25
53 22
")
Data$Age2 = Data$Age ^ 2
### Check the data frame
library(psych)
headTail(Data)
str(Data)
summary(Data)
Confidence intervals for r-squared by bootstrap
library(boot)
Function = function(input, index){
Input = input[index,]
Result = lm (Words.per.minute ~ Age + Age2,
data = Input)
Stat = summary(Result)$r.squared
return(Stat)}
### Test Function
n = length(Data[,1])
Function(Data, 1:n)
[1] 0.5009385
### Produce Stat estimate by bootstrap
Boot = boot(Data,
Function,
R=5000)
mean(Boot$t[,1])
[1] 0.5754582
### Produce confidence interval by
bootstrap
### (Note that values will varies for
each run)
boot.ci(Boot,
conf = 0.95,
type = "perc")
### Options: "norm", "basic", "stud",
"perc", "bca", "all"
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 1000 bootstrap replicates
Intervals :
Level Percentile
95% ( 0.3796, 0.7802 )
Calculations and Intervals on Original Scale
### Other information
Boot
hist(Boot$t[,1])
Confidence intervals for Efron’s pseudo r-squared by bootstrap
The efronRSquared function produces a single statistic. This makes it relatively easy to pass to the boot function.
library(boot)
library(rcompanion)
Function = function(input, index){
Input = input[index,]
Result = lm(Words.per.minute ~ Age + Age2,
data = Input)
Stat = efronRSquared(Result)
return(Stat)}
### Test Function
n = length(Data[,1])
Function(Data, 1:n)
[1] 0.501
### Produce Stat estimate by bootstrap
Boot = boot(Data,
Function,
R=1000)
mean(Boot$t[,1])
[1] 0.575913
### Produce confidence interval by
bootstrap
boot.ci(Boot,
conf = 0.95,
type = "perc")
### Options: "norm",
"basic", "stud", "perc", "bca",
"all"
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 1000 bootstrap replicates
CALL :
boot.ci(boot.out = Boot, conf = 0.95, type = "perc")
Intervals :
Level Percentile
95% ( 0.3930, 0.7639 )
Calculations and Intervals on Original Scale
### Other information
Boot
hist(Boot$t[,1],
col = "darkgray")
Confidence intervals for pseudo r-squared by bootstrap
The nagelkerke function produces a list. The second item in the list is a matrix named
Pseudo.R.squared.for.model.vs.null.
The third element of this matrix is the value for the Nagelkerke pseudo R-squared. So,
nagelkerke(Result, Null)[[2]][3]
yields the value of the Nagelkerke pseudo R-squared.
library(boot)
library(rcompanion)
Function = function(input, index){
Input = input[index,]
Result = glm (Words.per.minute ~ Age + Age2,
data = Input,
family="gaussian")
Null = glm (Words.per.minute ~ 1,
data = Input,
family="gaussian")
Stat = nagelkerke(Result, Null)[[2]][3]
return(Stat)}
### Test Function
n = length(Data[,1])
Function(Data, 1:n)
[1] 0.501964
### Produce Stat estimate by bootstrap
Boot = boot(Data,
Function,
R=1000)
### In this case, even 1000 iterations
can take a while
mean(Boot$t[,1])
[1] 0.5803598
### Produce confidence interval by
bootstrap
boot.ci(Boot,
conf = 0.95,
type = "perc")
### Options: "norm",
"basic", "stud", "perc", "bca",
"all"
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 1000 bootstrap replicates
Intervals :
Level Percentile
95% ( 0.3836, 0.7860 )
Calculations and Intervals on Original Scale
### Other information
Boot
hist(Boot$t[,1],
col = "darkgray")
References
IDRE . 2011. FAQ: What are pseudo R-squareds? UCLA. stats.oarc.ucla.edu/other/mult-pkg/faq/general/faq-what-are-pseudo-r-squareds/.
Kabacoff, R.I. 2017. Bootstrapping. Quick-R.