![[banner]](images/banner.jpg "Cohansey River, Fairfield, New Jersey")
Packages used in this chapter
The packages used in this chapter include:
• psych
• DescTools
• Rmisc
• FSA
• plyr
• boot
The following commands will install these packages if they are not already installed:
if(!require(psych)){install.packages("psych")}
if(!require(DescTools)){install.packages("DescTools")}
if(!require(Rmisc)){install.packages("Rmisc")}
if(!require(FSA)){install.packages("FSA")}
if(!require(plyr)){install.packages("plyr")}
if(!require(boot)){install.packages("boot")}
Descriptive statistics
Descriptive statistics are used to summarize data in a way that provides insight into the information contained in the data. This might include examining the mean or median of numeric data or the frequency of observations for nominal data. Plots can be created that show the data and indicating summary statistics.
Choosing which summary statistics are appropriate depend on the type of variable being examined. Different statistics are usually used for interval/ratio, ordinal, and nominal data.
In describing or examining data, you will typically be concerned with measures of location, variation, and shape.
Location is also called central tendency. It is a measure of the magnitude of the values of the data. For example, are the values close to 10 or 100 or 1000? Measures of location include mean and median, as well as somewhat less common statistics like M-estimators or Winsorized means.
Variation is also called dispersion. It is a measure of how far the data points lie from one another. Common statistics include standard deviation and coefficient of variation. For data that aren’t symmetrically-distributed, percentile, interquartile range, or median absolute deviation might be used.
Shape refers to the distribution of values. The best tools to evaluate the shape of data are histograms and related plots. Statistics include skewness and kurtosis, though they are often less useful than visual inspection. We can describe data shape as normally-distributed, log-normal, uniform, skewed, bi-modal, and others.
Descriptive statistics for interval/ratio data
For this example, imagine that Ren and Stimpy have each held eight workshops educating the public about water conservation at home. They are interested in how many people showed up to the workshops.
Because the data are housed in a data frame, we can use the convention Data$Attendees to access the variable Attendees within the data frame Data.
Data = read.table(header=TRUE, stringsAsFactors=TRUE, text="
Instructor Location Attendees
Ren North 7
Ren North 22
Ren North 6
Ren North 15
Ren South 12
Ren South 13
Ren South 14
Ren South 16
Stimpy North 18
Stimpy North 17
Stimpy North 15
Stimpy North 9
Stimpy South 15
Stimpy South 11
Stimpy South 19
Stimpy South 23
")
Data ### Will output data frame called
Data
str(Data) ### Shows the structure of the data
frame
summary(Data) ### Summarizes variables in the data
frame
Functions sum and length
The sum of a variable can be found with the sum function, and the number of observations can be found with the length function.
sum(Data$Attendees)
232
length(Data$Attendees)
16
Statistics of location for interval/ratio data
Mean
The mean is the arithmetic average, and is a common statistic used with interval/ratio data. It is simply the sum of the values divided by the number of values. The mean function in R will return the mean.
sum(Data$Attendees) / length(Data$Attendees)
14.5
mean(Data$Attendees)
14.5
Caution should be used when reporting mean values with skewed data, as the mean may not be representative of the center of the data. For example, imagine a town with 10 families, nine of whom have an income of less than $50, 000 per year, but with one family with an income of $2,000,000 per year. The mean income for families in the town would be $233,000, but this may not be a reasonable way to summarize the income of the town.
Income = c(49000, 44000, 25000, 18000, 32000, 47000, 37000, 45000, 36000, 2000000)
mean(Income)
233300
Median
The median is defined as the value below which 50% of the observations are found. To find this value manually, you would order the observations, and separate the lowest 50% from the highest 50%. For data sets with an odd number of observations, the median is the middle value. For data sets with an even number of observations, by convention, the median falls half-way between the two middle values.
The median is a robust statistic in that it is not affected by adding extreme values. For example, if we changed Stimpy’s last Attendees value from 23 to 1000, it would not affect the median.
median(Data$Attendees)
15
Attendees.2 = c(7, 22, 6, 15, 12, 13, 14, 16, 18, 17, 15, 9, 15, 11,
19, 1000)
Attendees.2
7 22 6 15 12 13 14 16 18 17 15 9 15 11 19 1000
median(Attendees.2)
15
The median is appropriate for either skewed or unskewed data. The median income for the town discussed above is $40,500. Half the families in the town have an income above this amount, and half have an income below this amount.
Income = c(49000, 44000, 25000, 18000, 32000, 47000, 37000, 45000,
36000, 2000000)
median(Income)
40500
Note that medians are sometimes reported as the “average person” or “typical family”. Saying, “The average American family earned $54,000 last year” means that the median income for families was $54,000. The “average family” is that one with the median income.
Mode
The mode is a summary statistic that is used rarely in practice, but is often included in a discussion of mean and medians. When there are discreet values for a variable, the mode is simply the value which occurs most frequently. For example, in the Statistics Learning Center video in the Required Readings below, Dr. Nic gives an example of counting the number of pairs of shoes each student owns. The most common answer was 10, and therefore 10 is the mode for that data set.
For our Ren and Stimpy example, the value 15 occurs three times and so is the mode.
The Mode function can be found in the package DescTools.
library(DescTools)
Mode(Data$Attendees)
15
Statistics of variation for interval/ratio data
Standard deviation
The standard deviation is a measure of variation which is commonly used with interval/ratio data. It’s a measurement of how close the observations in the data set are to the mean.
There’s a handy rule of thumb that—for normally distributed data—68% of data points fall within the mean ± 1 standard deviation, 95% of data points fall within the mean ± 2 standard deviations, and 99.7% of data points fall within the mean ± 3 standard deviations.
Because the mean is often represented with the letter mu, and the standard deviation is represented with the letter sigma, saying someone is “a few sigmas away from mu” indicates they are rather a rare character. (I originally heard this joke on an episode of Car Talk, for which I cannot find a reference or transcript.)
sd(Data$Attendees)
4.830459
Standard deviation may not be as useful for skewed data as it is for symmetric or normal data.
Median absolute deviation
The median absolute deviation is also a measure of variation used with interval/ratio data. It’s useful to measure the dispersion of the data when the distribution of the data is not symmetric or not known. By default, the mad() function in R adjusts the calculation for the median absolute deviation. For an unadjusted calculation, the constant = 1 option could be used.
mad(Data$Attendees)
4.4478
mad(Data$Attendees, constant=1)
3
Standard error of the mean
Standard error of the mean is a measure that estimates how close a calculated mean from a sample is likely to be to the true mean of that population. It is commonly used in tables or plots where multiple means are presented together. For example, we might want to present the mean attendees for Ren with the standard error for that mean and the mean attendees for Stimpy with the standard error that mean.
The standard error is the standard deviation divided by the square root of the number of observations. It can also be found in the output for the describe function in the psych package, labelled se.
sd(Data$Attendees) /
sqrt(length(Data$Attendees))
1.207615
library(psych)
describe(Data$Attendees)
vars n mean sd median trimmed mad min max range skew
kurtosis se
1 1 16 14.5 4.83 15 14.5 4.45 6 23 17 -0.04 -0.88 1.21
### se indicates the standard error of the mean
Five-number summary, quartiles, percentiles
The median is the same as the 50th percentile, because 50% of values fall below this value. Other percentiles for a data set can be identified to provide more information. Typically, the 0th, 25th, 50th, 75th, and 100th percentiles are reported. This is sometimes called the five-number summary.
These values can also be called the minimum, 1st quartile, 2nd quartile, 3rd quartile, and maximum.
The five-number summary is a useful measure of variation for skewed interval/ratio data or for ordinal data. 25% of values fall below the 1st quartile and 25% of values fall above the 3rd quartile. This leaves the middle 50% of values between the 1st and 3rd quartiles, giving a sense of the range of the middle half of the data. This range is called the interquartile range (IQR).
Percentiles and quartiles are relatively robust, as they aren’t affected much by a few extreme values. They are appropriate for both skewed and unskewed data.
summary(Data$Attendees)
Min. 1st Qu. Median Mean 3rd Qu. Max.
6.00 11.75 15.00 14.50 17.25 23.00
### The five-number summary and the mean
Optional technical note on calculating percentiles
It may have struck you as odd that the 3rd quartile for Attendees was reported as 17.25. After all, if you were to order the values of Attendees, the 75th percentile would fall between 17 and 18. But why does R go with 17.25 and not 17.5?
sort(Data$Attendees)
6 7 9 11 12 13 14 15 15 15 16 17 18 19 22 23
The answer is that there are several different methods to calculate percentiles, and they may give slightly different answers. For details on the calculations, see ?quantiles.
For Attendees, the default type 7 calculation yields a 75th percentile value of 17.25, whereas the type 2 calculation simply splits the difference between 17 and 18 and yields 17.5. The type 1 calculation doesn’t average the two values, and so just returns 17.
quantile(Data$Attendees, 0.75, type=7)
75%
17.25
quantile(Data$Attendees, 0.75, type=2)
75%
17.5
quantile(Data$Attendees, 0.75, type=1)
75%
17
Percentiles other than the 25th, 50th, and 75th can be calculated with the quantiles function. For example, to calculate the 95th percentile:
quantile(Data$Attendees, .95)
95%
22.25
The quantile() function can also determine the values for several quantiles in one call.
quantile(Data$Attendees, c(0.05, 0.10, 0.25, 0.50, 0.75, 0.90, 0.95), type = 7)
5% 10% 25% 50% 75% 90% 95%
6 7 11 15 17 22 23
You can also determine which quantile any given value would correspond to.
Values = c(5, 10, 15, 20, 25)
Quantiles = ecdf(Data$Attendees)(Values)
Quantiles = round(Quantiles, 2)
names(Quantiles) = Values
Quantiles
5 10 15 20 25
0.00 0.19 0.62 0.88 1.00
Statistics for grouped interval/ratio data
In many cases, we will want to examine summary statistics for a variable within groups. For example, we may want to examine statistics for the workshops lead by Ren and those lead by Stimpy.
Summarize in FSA
The Summarize function in the FSA package returns the number of observations, mean, standard deviation, minimum, 1st quartile, median, 3rd quartile, and maximum for grouped data.
Note the use of formula notation: Attendees is the dependent variable (the variable you want to get the statistics for); and Instructor is the independent variable (the grouping variable). Summarize allows you to summarize over the combination of multiple independent variables by listing them to the right of the ~ separated by a plus sign (+).
library(FSA)
Summarize(Attendees ~ Instructor,
data=Data)
Instructor n nvalid mean sd min Q1 median Q3 max
1 Ren 8 8 13.125 5.083236 6 10.75 13.5 15.25 22
2 Stimpy 8 8 15.875 4.454131 9 14.00 16.0 18.25 23
Summarize(Attendees ~ Instructor + Location,
data=Data)
Instructor Location n nvalid mean sd min Q1 median Q3 max
1 Ren North 4 4 12.50 7.505554 6 6.75 11.0 16.75 22
2 Stimpy North 4 4 14.75 4.031129 9 13.50 16.0 17.25 18
3 Ren South 4 4 13.75 1.707825 12 12.75 13.5 14.50 16
4 Stimpy South 4 4 17.00 5.163978 11 14.00 17.0 20.00 23
summarySE in Rmisc
The summarySE function in the Rmisc package outputs the number of observations, mean, standard deviation, standard error of the mean, and confidence interval for the mean for grouped data. The summarySE function allows you to summarize over the combination of multiple independent variables by listing them as a vector, e.g. c("Instructor", "Student").
library(Rmisc)
summarySE(data=Data,
"Attendees",
groupvars="Instructor",
conf.interval = 0.95)
Instructor N Attendees sd se ci
1 Ren 8 13.125 5.083236 1.797195 4.249691
2 Stimpy 8 15.875 4.454131 1.574773 3.723747
summarySE(data=Data,
"Attendees",
groupvars = c("Instructor", "Location"),
conf.interval = 0.95)
Instructor Location N Attendees sd se ci
1 Ren North 4 12.50 7.505553 3.7527767 11.943011
2 Ren South 4 13.75 1.707825 0.8539126 2.717531
3 Stimpy North 4 14.75 4.031129 2.0155644 6.414426
4 Stimpy South 4 17.00 5.163978 2.5819889 8.217041
describeBy in psych
The describeBy function in the psych package returns the number of observations, mean, median, trimmed means, minimum, maximum, range, skew, kurtosis, and standard error of the mean for grouped data. describeBy allows you to summarize over the combination of multiple independent variables by combining terms with a colon (:).
library(psych)
describeBy(Data$Attendees,
group = Data$Instructor,
digits= 4)
group: Ren
vars n mean sd median trimmed mad min max range skew kurtosis se
1 1 8 13.12 5.08 13.5 13.12 2.97 6 22 16 0.13 -1.08 1.8
-------------------------------------------------------------------------
group: Stimpy
vars n mean sd median trimmed mad min max range skew kurtosis se
1 1 8 15.88 4.45 16 15.88 3.71 9 23 14 -0.06 -1.26 1.57
describeBy(Data$Attendees,
group = Data$Instructor : Data$Location,
digits= 4)
group: Ren:North
vars n mean sd median trimmed mad min max range skew kurtosis se
1 1 4 12.5 7.51 11 12.5 6.67 6 22 16 0.26 -2.14 3.75
-------------------------------------------------------------------------
group: Ren:South
vars n mean sd median trimmed mad min max range skew kurtosis se
1 1 4 13.75 1.71 13.5 13.75 1.48 12 16 4 0.28 -1.96 0.85
-------------------------------------------------------------------------
group: Stimpy:North
vars n mean sd median trimmed mad min max range skew kurtosis se
1 1 4 14.75 4.03 16 14.75 2.22 9 18 9 -0.55 -1.84 2.02
-------------------------------------------------------------------------
group: Stimpy:South
vars n mean sd median trimmed mad min max range skew kurtosis se
1 1 4 17 5.16 17 17 5.93 11 23 12 0 -2.08 2.58
Summaries for data frames
Often we will want to summarize variables in a whole data frame, either to get some summary statistics for individual variables, or to check that variables have the values we expected in inputting the data, to be sure there wasn’t some error.
The str function
The str function in the native utils package will list variables for a data frame, with their types and levels. Data is the name of the data frame, created above.
str(Data)
'data.frame': 16 obs. of 3 variables:
$ Instructor: Factor w/ 2 levels "Ren","Stimpy": 1 1 1 1 1
1 1 1 2 2 ...
$ Location : Factor w/ 2 levels "North","South": 1 1 1 1
2 2 2 2 1 1 ...
$ Attendees : int 7 22 6 15 12 13 14 16 18 17 ...
### Instructor is a factor (nominal) variable with
two levels.
### Location is a factor (nominal) variable with two levels.
### Attendees is an integer variable.
The summary function
The summary function in the native base package will summarize all variables in a data frame, listing the frequencies for levels of nominal variables; and for interval/ratio data, the minimum, 1st quartile, median, mean, 3rd quartile, and maximum.
summary(Data)
Instructor Location Attendees
Ren :8 North:8 Min. : 6.00
Stimpy:8 South:8 1st Qu.:11.75
Median :15.00
Mean :14.50
3rd Qu.:17.25
Max. :23.00
The headTail function in psych
The headTail function in the psych package reports the first and last observations for a data frame.
library(psych)
headTail(Data)
Instructor Location Attendees
1 Ren North 7
2 Ren North 22
3 Ren North 6
4 Ren North 15
... <NA> <NA> ...
13 Stimpy South 15
14 Stimpy South 11
15 Stimpy South 19
16 Stimpy South 23
The head and tail functions in the native utils package reports the first and last observations for a data frame.
head(Data, n=10)
Instructor Location Attendees
1 Ren North 7
2 Ren North 22
3 Ren North 6
4 Ren North 15
5 Ren South 12
6 Ren South 13
7 Ren South 14
8 Ren South 16
9 Stimpy North 18
10 Stimpy North 17
tail(Data, n=10)
Instructor Location Attendees
7 Ren South 14
8 Ren South 16
9 Stimpy North 18
10 Stimpy North 17
11 Stimpy North 15
12 Stimpy North 9
13 Stimpy South 15
14 Stimpy South 11
15 Stimpy South 19
16 Stimpy South 23
The describe function in psych
The describe function in the psych package reports number of observations, mean, standard deviation, trimmed means, minimum, maximum, range, skew, kurtosis, and standard error for variables in a data frame.
Note that factor variables are labeled with an asterisk (*), and the levels of the factors are coded as 1, 2, 3, etc.
library(psych)
describe(Data)
vars n mean sd
median trimmed mad min max range skew kurtosis se
Instructor* 1 16 1.5 0.52 1.5 1.5 0.74 1 2 1 0.00 -2.12
0.13
Location* 2 16 1.5 0.52 1.5 1.5 0.74 1 2 1 0.00 -2.12
0.13
Attendees 3 16 14.5 4.83 15.0 14.5 4.45 6 23 17 -0.04 -0.88
1.21
Dealing with missing values
Sometimes a data set will have missing values. This can occur for a variety of reasons, such as a respondent not answering a specific question, or a researcher being unable to make a measurement due to temporarily malfunctioning equipment.
In R, a missing value is indicated with NA.
By default, different functions in R will handle missing values in different ways. But most have options to change how they treat missing data.
In general, you should scan your data for missing data, and think carefully about the best way to handle observations with missing values.
Data2 = read.table(header=TRUE, stringsAsFactors=TRUE, text="
Instructor Location Attendees
Ren North 7
Ren North 22
Ren North 6
Ren North 15
Ren South 12
Ren South 13
Ren South NA
Ren South 16
Stimpy North 18
Stimpy North 17
Stimpy North NA
Stimpy North 9
Stimpy South 15
Stimpy South 11
Stimpy South 19
Stimpy South 23
")
### Note: This data frame will be called Data2
to distinguish it
### from Data above.
Data2
The na.rm option for missing values with a simple function
Many common functions in R have a na.rm option. If this option is set to FALSE, the function will return an NA result if there are any NA’s in the data values passed to the function. If set to TRUE, observations with NA values will be discarded, and the function will continue to calculate its output.
Note that the na.rm option operates only on the data values actually passed to the function. In the following example with median, only Attendees is passed to the function; if there were NA’s in other variables, this would not affect the function.
Not all functions have the same default for the na.rm option. To determine the default, use e.g. ?median, ?mean, ?sd.
median(Data2$Attendees,
na.rm = FALSE)
NA
### na.rm=FALSE. Since there is an NA in the
data, report NA.
median(Data2$Attendees,
na.rm = TRUE)
15
### na.rm=TRUE. Drop observations with NA and
then calculate the median.
Missing values with Summarize in FSA
Summarize in FSA will indicate invalid values, including NA’s, with the count of valid observations outputted as the variable nvalid.
library(FSA)
Summarize(Attendees ~ Instructor,
data=Data2)
Instructor n nvalid mean sd min Q1 median Q3 max
1 Ren 8 7 13 5.477226 6 9.5 13 15.5 22
2 Stimpy 8 7 16 4.795832 9 13.0 17 18.5 23
### This function removes missing values, but
indicates the number of
### missing values by not including them in the count for nvalid.
Missing values indicated with summary function
The summary function counts NA’s for numeric variables.
summary(Data2)
Instructor Location Attendees
Ren :8 North:8 Min. : 6.00
Stimpy:8 South:8 1st Qu.:11.25
Median :15.00
Mean :14.50
3rd Qu.:17.75
Max. :23.00
NA's :2
### Indicates two NA’s in Attendees.
Missing values in the describe function in psych
The describe function is the psych package removes NA’s by default.
library(psych)
describe(Data2$Attendees)
vars n mean sd median trimmed mad min max range skew kurtosis se
1 1 14 14.5 5.19 15 14.5 5.19 6 23 17 -0.04 -1.17 1.39
### Note that two NA’s were removed by default,
reporting an n of 14.
Missing values in the summarySE function in Rmisc
By default, the summarySE function does not remove NA’s, but can be made to do so with the na.rm=TRUE option.
library(Rmisc)
summarySE(data=Data2,
"Attendees")
.id N Attendees sd se ci
1 <NA> 16 NA NA NA NA
### Note an N of 16 is reported, and statistics
are reported as NA.
library(Rmisc)
summarySE(data=Data2,
"Attendees",
na.rm=TRUE)
.id N Attendees sd se ci
1 <NA> 14 14.5 5.185038 1.38576 2.993752
### Note an N of 14 is reported, and statistics
are calculated with
### NA’s removed.
Advanced techniques
Discarding subjects
Certain psychology studies use scales that are calculated from responses of several questions. Because answers to all questions are needed to reliably calculate the scale, any observation (subject, person) with missing answers will simply be discarded. Some types of analyses in other fields also follow this approach.
Subjects can be deleted with the subset function. The following code creates a new data frame, Data3, with all observations with NA in the variable Attendees removed from Data2.
Data3 = subset(Data2,
!is.na(Attendees))
Data3
Instructor Location Attendees
1 Ren North 7
2 Ren North 22
3 Ren North 6
4 Ren North 15
5 Ren South 12
6 Ren South 13
8 Ren South 16
9 Stimpy North 18
10 Stimpy North 17
12 Stimpy North 9
13 Stimpy South 15
14 Stimpy South 11
15 Stimpy South 19
16 Stimpy South 23
### Note in the results that observations 7 and 11
were deleted
Imputation of values
Missing values can be assigned a likely value through the process of imputation. An algorithm is used that determines a value based on the values of other variables for that observation relative to values for other variables. The mice package in R can perform imputation.
Optional code: removing missing values in vectors
If functions don’t have a na.rm option, it is possible to remove NA observations manually. Here we’ll create a vector called valid that just contains those values of Attendees that are not NA’s.
The ! operator is a logical not. The brackets serve as a list of observations to include for the preceding variable. So, the code essentially says, “Define a vector valid as the values of Attendees where the values of Attendees are not NA.”
valid = Data2$Attendees[!is.na(Data2$Attendees)]
valid
7 22 6 15 12 13 16 18 17 9 15 11 19 23
summary(valid)
Min. 1st Qu. Median Mean 3rd Qu. Max.
6.00 11.25 15.00 14.50 17.75 23.00
Statistics of shape for interval/ratio data
Perhaps the most common statistics describing the shape of a data distribution are skewness and kurtosis.
Skewness and kurtosis values are not reported too commonly. Instead, the shape of observed data is often presented visually with plot, such as a histogram or quantile-quantile plot.
Skewness
Skewness indicates the degree of asymmetry in a data set. If the distribution shows a long tail to the right, the distribution is positively skewed or right skewed. Negative or left skew is the opposite.
A symmetric distribution has a skewness of 0. The skewness value for a positively skewed distribution is positive, and a negative value describes a negatively skewed distribution. Sometimes a skew with an absolute value greater than 1 or 1.5 or 2 is considered highly skewed. There is not agreement on this interpretation.
There are different methods to calculate skew and kurtosis. The describe function in the psych package has three options for how to calculate them.
library(psych)
describe(Data$Attendees,
type=3) ### Type of calculation
for skewness and kurtosis
vars n mean sd median trimmed mad min max range skew
kurtosis se
1 1 16 14.5 4.83 15 14.5 4.45 6 23 17 -0.04 -0.88 1.21
### Skewness and kurtosis among other statistics


The normal curve is symmetrical
around its center. The positively-skewed distribution has a longer,
thicker tail to the right. The negatively-skewed distribution
has a longer, thicker tail to the left.
Normal distribution
The normal distribution is symmetric, bell-shaped, and follows a specific mathematically-defined distribution. No real observed data is exactly normally distributed, but some real-world data are approximately normal in distribution.
For more information on the normal distribution, see the video on “Normal Distribution” from Statistics Learning Center in the “Optional Readings” section. Additional thoughts on the normal distribution and real-world data distributions are in the article by Dr. Nic in the “Optional Readings” section.
Kurtosis
Kurtosis measures the degree to which the distribution of data has either fewer and less extreme outliers, or more and more extreme outliers, where outliers are values that are far from the center of the distribution. This can be thought of as how thick the tails are in a distribution. A normal distribution is mesokutic.
In general, the higher the kurtosis, the sharper the peak and the fatter the tails. This is called leptokurtic, and is indicated by positive kurtosis values. The opposite—platykurtosis—has negative kurtosis values, with a flatter peak and thinner tails.
However, kurtosis doesn’t necessarily measure the “peakedness” of the distribution, or even the fatness of the tails of the distribution. It’s a difficult concept to encapsulate in the general case.
Confusingly, the kurtosis for a normal distribution is sometimes defined as 0, and sometimes defined as 3. The former is often called “excess kurtosis”.
Sometimes an excess kurtosis with an absolute value greater than 2 or 3 is considered a high deviation from being mesokurtic. There is not agreement on this interpretation.
Descriptive statistics for ordinal data
Descriptive statistics for ordinal data are more limited than those for interval/ratio data. You’ll remember that for ordinal data, the levels can be ordered, but we can’t say that the intervals between the levels are equal. For example, we can’t say that an Associate’s degree and Master’s degree somehow average out to a Bachelor’s degree.
Because of this fact, several common descriptive statistics are usually inappropriate for use with ordinal data. These include mean and standard deviation.
Ordinal data can be described by either: 1) treating the data as numeric and using appropriate statistics such as median and quartiles; or, 2) treating the data as nominal, and looking at counts or proportions of the data for each level.
A more-complete discussion of descriptive statistics for ordinal data can be found in the Descriptive Statistics for Likert Data chapter.
Example of descriptive statistics for ordinal data
For this example, imagine that Arthur and Baxter have each held a workshop educating the public about preventing water pollution at home. They are interested in the education level of people who attended the workshops. We can consider education level an ordinal variable. They also collected information on the gender and county of participants.
For this data, we have manually coded Education with numbers in a separate variable Ed.code. These numbers list the education in order: High school < Associate’s < Bachelor’s < Master’s < Ph.D.
Of course we could have had R do this coding for us, but the code is slightly messy, so I did the coding manually, and listed the optional R code below.
Ideally, we would want to treat Education as an ordered factor variable in R. But unfortunately, most common functions in R won’t handle ordered factors well. Later in this book, ordered factor data will be handled directly with cumulative link models (CLM), permutation tests, and tests for ordered tables.
Data = read.table(header=TRUE, stringsAsFactors=TRUE, text="
Date Instructor Student Gender County Education Ed.code
'2015-11-01' 'Arthur Read' a female 'Elwood' BA 3
'2015-11-01' 'Arthur Read' b female 'Bear Lake' PHD 5
'2015-11-01' 'Arthur Read' c male 'Elwood' BA 3
'2015-11-01' 'Arthur Read' d female 'Elwood' MA 4
'2015-11-01' 'Arthur Read' e male 'Elwood' HS 1
'2015-11-01' 'Arthur Read' f female 'Bear Lake' MA 4
'2015-11-01' 'Arthur Read' g male 'Elwood' HS 1
'2015-11-01' 'Arthur Read' h female 'Elwood' BA 3
'2015-11-01' 'Arthur Read' i female 'Elwood' BA 3
'2015-11-01' 'Arthur Read' j female 'Elwood' BA 3
'2015-12-01' 'Buster Baxter' k male 'Elwood' MA 4
'2015-12-01' 'Buster Baxter' l male 'Bear Lake' MA 4
'2015-12-01' 'Buster Baxter' m female 'Elwood' AA 2
'2015-12-01' 'Buster Baxter' n male 'Elwood' AA 2
'2015-12-01' 'Buster Baxter' o other 'Elwood' BA 3
'2015-12-01' 'Buster Baxter' p female 'Elwood' BA 3
'2015-12-01' 'Buster Baxter' q female 'Bear Lake' PHD 5
")
### Check the data frame
Data
str(Data)
'data.frame': 17 obs. of 7 variables:
$ Date : Factor w/ 2 levels
"2015-11-01","2015-12-01": 1 1 1 1 1 1 1 1 1 1
$ Instructor: Factor w/ 2 levels "Arthur Read",..: 1 1 1 1 1 1 1 1 1
1 ...
$ Student : Factor w/ 17 levels
"a","b","c","d",..: 1 2 3 4 5 6 7 8 9
10 ...
$ Gender : Factor w/ 3 levels "female","male",..: 1 1 2
1 2 1 2 1 1 1 ...
$ County : Factor w/ 2 levels "Bear Lake","Elwood": 2 1
2 2 2 1 2 2 2 2 ...
$ Education : Factor w/ 5 levels
"AA","BA","HS",..: 2 5 2 4 3 4 3 2 2 2 ...
$ Ed.code : int 3 5 3 4 1 4 1 3 3 3 ...
summary(Data)
Date Instructor Student Gender County
2015-11-01:10 Arthur Read :10 a : 1 female:10 Bear Lake: 4
2015-12-01: 7 Buster Baxter: 7 b : 1 male : 6 Elwood :13
c : 1 other : 1
d : 1
e : 1
f : 1
(Other):11
Education Ed.code
AA :2 Min. :1.000
BA :7 1st Qu.:3.000
HS :2 Median :3.000
MA :4 Mean :3.118
PHD:2 3rd Qu.:4.000
Max. :5.00
Code to assign values to a variable based on another variable
Data$Ed.code[Data$Education=="HS"] = 1
Data$Ed.code[Data$Education=="AA"] = 2
Data$Ed.code[Data$Education=="BA"] = 3
Data$Ed.code[Data$Education=="MA"] = 4
Data$Ed.code[Data$Education=="PHD"] = 5
Code to change a factor variable to an ordered factor variable
Data$Education.ordered = factor(Data$Education,
ordered = TRUE,
levels = c("HS", "AA",
"BA", "MA", "PHD")
)
str(Data$Education.ordered)
summary(Data$Education.ordered)
HS AA BA MA PHD
2 2 7 4 2
Statistics of location for ordinal data
Using the mean is usually not appropriate for ordinal data. Instead, the median could be used as a measure of location. We will use our numerically-coded variable Ed.code for the analysis.
median(Data$Ed.code)
3
### Remember that 3 meant Bachelor’s degree in our
coding
R no longer allows you to use the median() function on an ordered factor variable.
median(Data$Education.ordered)
Error in median.default(Data$Education.ordered) : need numeric data
However, the quantile() function can be use to get the median and other quantiles.
quantile(Data$Education.ordered, c(0.25, 0.50, 0.75), type=3)
25% 50% 75%
AA BA MA
Levels: HS < AA < BA < MA < PHD
Or the median() function can be used for an ordered factor variable in an indirect way.
levels(Data$Education.ordered)[median(as.numeric(Data$Education.ordered))]
"BA"
Statistics of variation for ordinal data
Statistics like standard deviation and standard error of the mean are usually inappropriate for ordinal data. Instead, the five-number summary can be used.
summary(Data$Ed.code)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 3.000 3.000 3.118 4.000 5.000
### Remember to ignore the mean value for ordinal
data.
### Remember that 1 meant High school, 3 meant Bachelor’s,
### 4 meant Master’s, and 5 meant Ph.D.
Statistics for grouped ordinal data
Because the Summarize function in the FSA package reports the five-number summary, it is a useful function for descriptive statistics for grouped ordinal data.
library(FSA)
Summarize(Ed.code ~ Gender,
data=Data)
Gender n nvalid mean sd min Q1 median Q3 max
1 female 10 10 3.5 0.9718253 2 3.00 3.0 4.00 5
2 male 6 6 2.5 1.3784049 1 1.25 2.5 3.75 4
3 other 1 1 3.0 NA 3 3.00 3.0 3.00 3
### Remember to ignore the mean and sd values for ordinal data.
library(FSA)
Summarize(Ed.code ~ Gender + County,
data=Data)
Gender County n nvalid mean sd min Q1 median Q3 max
1 female Bear Lake 3 3 4.666667 0.5773503 4 4.5 5 5 5
2 male Bear Lake 1 1 4.000000 NA 4 4.0 4 4 4
3 female Elwood 7 7 3.000000 0.5773503 2 3.0 3 3 4
4 male Elwood 5 5 2.200000 1.3038405 1 1.0 2 3 4
5 other Elwood 1 1 3.000000 NA 3 3.0 3 3 3
### Remember to ignore the mean and sd values for ordinal data.
Statistics for ordinal data treated as nominal data
The summary function in the native base package and the xtabs function in the native stats package provide counts for levels of a nominal variable.
The prop.table function translates a table into proportions. The margin=1 option indicates that the proportions are calculated for each row.
First, we will order the levels of Education, otherwise R with report results in alphabetical order.
Data$Education = factor(Data$Education,
levels = c("HS", "AA",
"BA", "MA", "PHD"))
### Order factors, otherwise R will alphabetize
them
summary(Data$Education)
HS AA BA MA PHD
2 2 7 4 2
### Counts of each level of
Education
XT = xtabs( ~ Education,
data=Data)
XT
Education
HS AA BA MA PHD
2 2 7 4 2
prop.table(XT)
Education
HS AA BA MA PHD
0.1176471 0.1176471 0.4117647 0.2352941 0.1176471
Grouped data
XT = xtabs( ~ Gender + Education,
data = Data)
XT
Education
Gender HS AA BA MA PHD
female 0 1 5 2 2
male 2 1 1 2 0
other 0 0 1 0 0
prop.table(XT,
margin = 1)
Education
Gender HS AA BA MA PHD
female 0.0000000 0.1000000 0.5000000 0.2000000 0.2000000
male 0.3333333 0.1666667 0.1666667 0.3333333 0.0000000
other 0.0000000 0.0000000 1.0000000 0.0000000 0.0000000
### Proportion of responses for each row
Two-way grouped data
XT = xtabs(~ Gender + Education + County,
data=Data)
XT
### Note that the dependent variable,
Education, is the middle
### of the variable list.
, , County = Bear Lake
Education
Gender HS AA BA MA PHD
female 0 0 0 1 2
male 0 0 0 1 0
other 0 0 0 0 0
, , County = Elwood
Education
Gender HS AA BA MA PHD
female 0 1 5 1 0
male 2 1 1 1 0
other 0 0 1 0 0
Descriptive statistics for nominal data
Descriptive statistics for nominal data consist of listing or plotting counts for levels of the nominal data, often by levels of a grouping variable. Tables of this information are often called contingency tables.
For this example, we will look again at Arthur and Buster’s data, but this time considering Gender to be the dependent variable of interest.
If levels of a nominal variable are coded with numbers, remember that the numbers will be arbitrary. For example, if you assign female = 1, and male = 2, and other = 3, it makes no sense to say that the average gender in Arthur’s class was 1.3. Or that the average gender in Buster’s class was greater than that in Arthur’s. It also makes no sense to say that the median gender was female.
Data = read.table(header=TRUE, stringsAsFactors=TRUE, text="
Date Instructor Student Gender County Education Ed.code
'2015-11-01' 'Arthur Read' a female 'Elwood' BA 3
'2015-11-01' 'Arthur Read' b female 'Bear Lake' PHD 5
'2015-11-01' 'Arthur Read' c male 'Elwood' BA 3
'2015-11-01' 'Arthur Read' d female 'Elwood' MA 4
'2015-11-01' 'Arthur Read' e male 'Elwood' HS 1
'2015-11-01' 'Arthur Read' f female 'Bear Lake' MA 4
'2015-11-01' 'Arthur Read' g male 'Elwood' HS 1
'2015-11-01' 'Arthur Read' h female 'Elwood' BA 3
'2015-11-01' 'Arthur Read' i female 'Elwood' BA 3
'2015-11-01' 'Arthur Read' j female 'Elwood' BA 3
'2015-12-01' 'Buster Baxter' k male 'Elwood' MA 4
'2015-12-01' 'Buster Baxter' l male 'Bear Lake' MA 4
'2015-12-01' 'Buster Baxter' m female 'Elwood' AA 2
'2015-12-01' 'Buster Baxter' n male 'Elwood' AA 2
'2015-12-01' 'Buster Baxter' o other 'Elwood' BA 3
'2015-12-01' 'Buster Baxter' p female 'Elwood' BA 3
'2015-12-01' 'Buster Baxter' q female 'Bear Lake' PHD 5
")
### Check the data frame
Data
str(Data)
summary(Data)
Example of descriptive statistics for nominal data
The summary function in the native base package and the xtabs function in the native stats package provide counts for levels of a nominal variable.
The prop.table function translates a table into proportions. The margin=1 option indicates that the proportions are calculated for each row.
One-sample data
summary(Data$Gender)
female male other
10 6 1
### Counts of each level of Gender
One-way data
xtabs(~ Date + Gender,
data=Data)
Gender
Date female male other
2015-11-01 7 3 0
2015-12-01 3 3 1
XT = xtabs(~ Date + Gender,
data=Data)
prop.table(XT,
margin = 1)
Gender
Date female male other
2015-11-01 0.7000000 0.3000000 0.0000000
2015-12-01 0.4285714 0.4285714 0.1428571
### Proportion of each level of Gender for each
row
sum(XT)
[1] 17
### Sum of observation in the table
rowSums(XT)
2015-11-01 2015-12-01
10 7
### Sum of observation in each row of the table
colSums(XT)
female male other
10 6 1
### Sum of observation in each column of the table
Two-way data
xtabs(~ County + Gender + Date,
data=Data)
### Note that the dependent variable, Gender,
is the middle
### of the variable list.
, , Date = 2015-11-01
Gender
County female male other
Bear Lake 2 0 0
Elwood 5 3 0
, , Date = 2015-12-01
Gender
County female male other
Bear Lake 1 1 0
Elwood 2 2 1
Levels for factor variables
Most of the time in R, nominal variables will be handled by the software as factor variables.
The order of levels of factor variables are important because most functions, including plotting functions, will handle levels of the factor in order. The order of the levels can be changed, for example, to change the order that groups are plotted in a plot, or which groups are at the top of the table.
The stringsAsFactors=TRUE option tells R to interpret character data as factor variables in the read.table call. By default, R alphabetizes the levels of the factors.
Looking at the Arthur and Buster data, note that Instructor, Student, Gender, among other variables, are treated as factor variables.
str(Data)
'data.frame': 17 obs. of 7 variables:
$ Date : Factor w/ 2 levels
"2015-11-01","2015-12-01": 1 1 1 1 1 1 1 1
$ Instructor: Factor w/ 2 levels "Arthur Read",..: 1 1 1 1 1 1 1 1 1
1 ...
$ Student : Factor w/ 17 levels "a","b","c","d",..:
1 2 3 4 5 6 7 8 9 10 .
$ Gender : Factor w/ 3 levels "female","male",..: 1 1 2
1 2 1 2 1 1 1 ...
$ County : Factor w/ 2 levels "Bear Lake","Elwood": 2 1
2 2 2 1 2 2 2 2 .
$ Education : Factor w/ 5 levels
"AA","BA","HS",..: 2 5 2 4 3 4 3 2 2 2 ...
$ Ed.code : int 3 5 3 4 1 4 1 3 3 3 ...
Note also that the levels of the factor variables were alphabetized by default. That is, even though Elwood was found in the data before Bear Lake, R treats Bear Lake as the first level in the variable County.
summary(Data)
Date Instructor Gender County
2015-11-01:10 Arthur Read :10 female:10 Bear Lake: 4
2015-12-01: 7 Buster Baxter: 7 male : 6 Elwood :13
other : 1
We can order factor levels by the order in which they were read in the data frame.
Data$County = factor(Data$County,
levels=unique(Data$County))
levels(Data$County)
[1] "Elwood" "Bear Lake"
We can also order factor levels in an order of our choosing.
Data$Gender = factor(Data$Gender,
levels=c("male" , "female", "other"))
levels(Data$Gender)
[1] "male" "female" "other"
Note that in the actions above, we are not changing the order in the data frame, simply which level is treated internally by the software as "1" or "2", and so on.
Optional note on reporting summary statistics honestly
Every time we report a descriptive statistic or the result of a statistical test, we are condensing information, which may have been a whole data set, into one or a few pieces of information. It is the job of the analyst to choose the best way to present descriptive and graphical information, and to choose the correct statistical test or method.
SAT score example
Imagine a set of changes in SAT scores from seven students who took a certain SAT preparation course. The change in scores, Increase, represents the difference in score; that is, the score after taking the course minus their initial score.
Increase = c(50, 60, 120, -80, -10, 10, 0)
Our first instinct in assessing the course might be to look at the average (mean) change in score. The result is a mean increase of 21 points, which could be considered a success, perhaps.
mean(Increase)
[1] 21.42857
But we would be remiss to not look at other summary statistics and plots.
Using the Summarize function in the FSA package, we find that the median increase was only 10 points. The increase for the first quartile was negative, suggesting at least 25% of students got a lower score afterwards.
library(FSA)
Summarize(Increase,
digits = 2)
n nvalid mean sd min Q1 median Q3
max
7.00 7.00 21.43 63.09 -80.00 -5.00 10.00 55.00
120.00
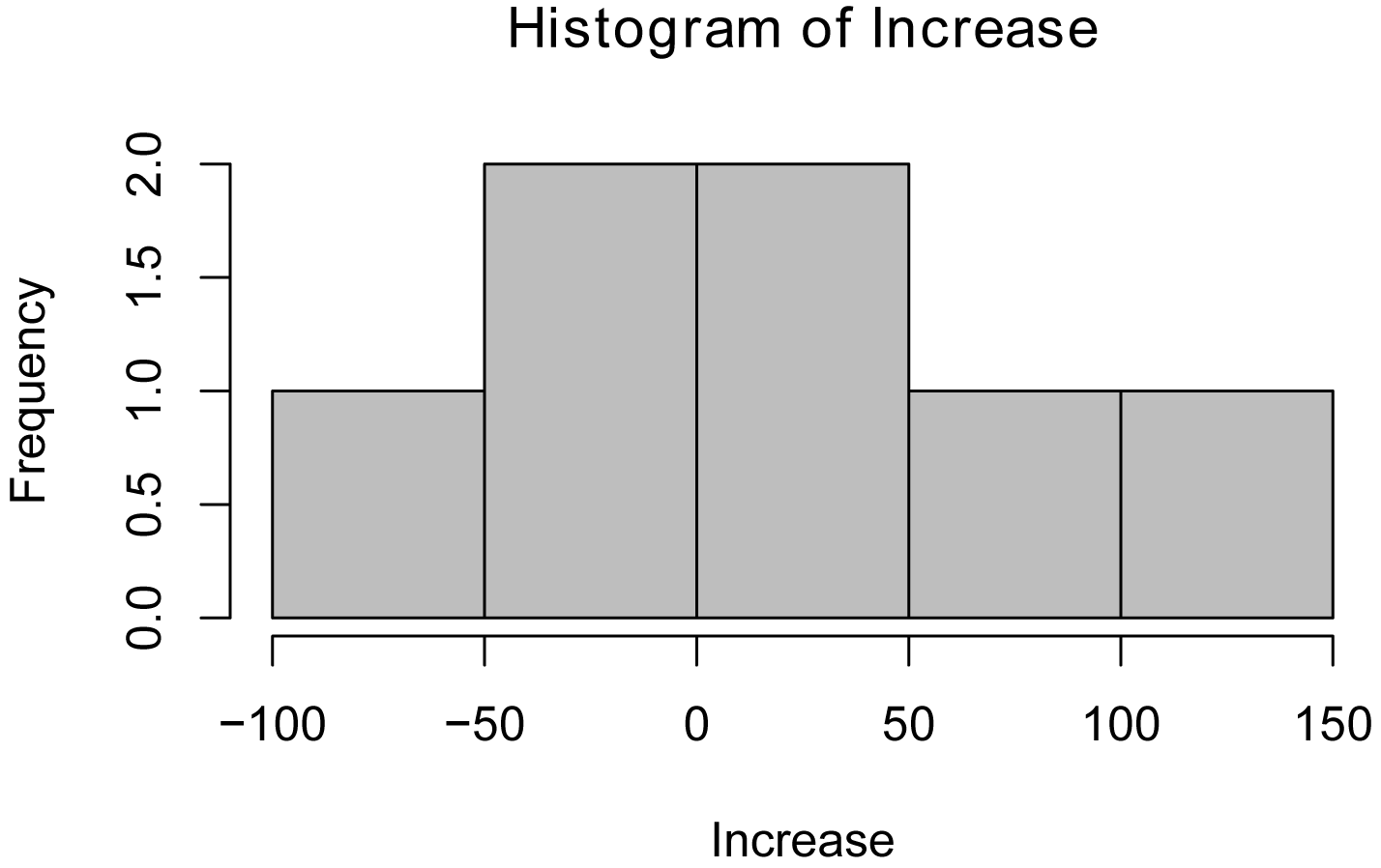
A histogram of the changes in scores suggests a slight right skew to the data, but that the mass of the data sits not far from zero.
hist(Increase,
col="gray")
Finally, we’ll compute the 95% confidence intervals for the mean change in score. Looking at the results for the percentile method, the confidence interval includes zero, suggesting the change in scores for this course were not statistically different from zero.
library(rcompanion)
Data = data.frame(Increase)
groupwiseMean(Increase ~ 1,
data = Data,
traditional = FALSE,
percentile = TRUE)
.id n Mean Conf.level Percentile.lower Percentile.upper
1 <NA> 7 21.4 0.95 -21.4 65.7
Based on the data exploration, it seems that it would be irresponsible or dishonest to simply report that the average increase in test scores was 20 points.
For descriptive statistics, we might report the mean and 95% confidence interval. Or perhaps the 5-point summary for the change in scores. Or show the histogram of values.
Optional analyses
Robust estimators: trimmed mean and Winsorized mean
Robust estimators of central tendency are used to describe the location of a data set without undue influence of extreme values. Robust estimators include trimmed means, Winsorized means, and other estimates like M-estimators (not discussed here).
Envirothon example
The New Jersey Envirothon is a statewide competition for high school students covering various aspects of natural resources science. In the Team Presentation station, student teams are judged by five judges.
Currently, scorekeepers drop the highest and lowest scores for each team to avoid the effect of aberrant low or high scores. This is an example of a trimmed mean. In this case, the mean is trimmed to 60% (with 20% removed from each side).
Another option to ameliorate the effect of extreme scores is using Winsorized means. A Winsorized mean removes extreme observations, but replaces them with the closest observations in terms of magnitude.
In this example, two teams received five scores for their presentations that have the same mean and median. We will look at robust estimators to determine if one team should be scored higher than the other.
Team.A = c(100, 90, 80, 60, 20)
median(Team.A)
[1] 80
mean(Team.A)
[1] 70
mean(Team.A,
trim = 0.20) # This trims to the
inner 60% of observations
[1] 76.66667
library(psych)
winsor(Team.A,
trim = 0.20) # This Winsorizes to
the inner 60% of observations
[1] 92 90 80 60 52
### Note that the Winsorized values at the
extremes appear to be calculated
### with a function analogous to the quantile(x, probs, type = 7)
function.
winsor.mean(Team.A,
trim = 0.20) # This Winsorizes to
the inner 60% of observations
[1] 74.8
Team.B = c(80, 80, 80, 80, 30)
median(Team.B)
[1] 80
mean(Team.B)
[1] 70
mean(Team.B,
trim = .20) # This trims to the
inner 60% of observations
[1] 80
library(psych)
winsor(Team.B,
trim = 0.20) # This Winsorizes to
the inner 60% of observations
[1] 80 80 80 80 70
### Note that the Winsorized values at the extremes
appear to be calculated
### with a function analogous to the quantile(x, probs, type = 7)
function.
winsor.mean(Team.B,
trim = 0.20) # This Winsorizes to the inner 60% of observations
[1] 78
In this example, the means and medians for Team A and Team B were identical. However, the trimmed mean for Team A was less than for Team B (77 vs. 80), and the Winsorized mean for A was less than for Team B (75 vs. 78). According to either the trimmed mean method or the Winsorized mean method, Team B had a higher score.
Note also that the Winsorized means were lower than for the trimmed means, for both teams. This is because the Winsorized mean is better able to take into account the low scores for each team.
Geometric mean
The geometric mean is used to summarize certain measurements, such as average return for investments, and for certain scientific measurements, such as bacteria counts in environmental water. It is useful when data are log-normally distributed.
Practically speaking, using the geometric mean ameliorates the effect of outlying values in the data.
To get the geometric mean, the log of each value is taken, these values are averaged, and then the result is the base of the log raised to this value.
Imagine a series of 9 counts of bacteria from lake water samples, called Bacteria here. The geometric mean can be calculated with a nested log, mean, and exp functions. Or more simply, the geometric.mean function in the psych package can be used.
Bacteria example
Bacteria = c(20, 40, 50, 60, 100, 120, 150, 200, 1000)
exp(mean(log(Bacteria)))
[1] 98.38887
library(psych)
geometric.mean(Bacteria)
[1] 98.38887
hist(Bacteria, ### Produce a histogram of values
col="darkgray",
breaks="FD")
Average annual return example
Geometric means are also used to calculate the average annual return for investments. Each value in this vector represents the percent return of the investment each year. The arithmetic mean will not give the correct answer for average annual return.
Return = c(-0.80, 0.20, 0.30, 0.30, 0.20, 0.30)
library(psych)
geometric.mean(Return + 1)-1
-0.07344666
### The geometric mean will give the correct
answer for average
### annual return
This can also be calculated manually. If you start with 100 dollars with this investment, you will end up with 63 dollars, equivalent to a return of – 0.07 per year for six years.
100 * (1-0.80) * 1.20 * 1.30 * 1.30 * 1.20 * 1.30
63.2736
The prod() function could be used to do this calculation with the Return vector.
100 * prod(Return + 1 )
63.2736
To see this play out step-by-step, a for() loop could be used. This returns the dollars remaining at each year given the actual return in the Return vector.
A = 100
for(i in 1:length(Return)){
A = A * (Return[i] + 1)
print(A)
}
20
24
31.2
40.56
48.672
63.2736
To see that this is equivalent to an average annual return from the geometric mean, we can use another loop, this time using AVR as a vector with the value of -0.07344666.
AVR = rep(geometric.mean(Return + 1)-1, length(Return))
A = 100
for(i in 1:length(AVR)){
A = A * (AVR[i] + 1)
print(A)
}
92.65533
85.85011
79.5447
73.70241
68.28922
63.2736
Harmonic mean
The harmonic mean is another type of average that is used in certain situations, such as averaging rates or speeds.
To get the harmonic mean, the inverse of each value is taken, these values are averaged, and then the inverse of this result is reported.
Imagine a series of 9 speeds, called Speed here. The harmonic mean can be calculated with a nested 1/x, mean, and 1/x functions. Or more simply, the harmonic.mean function in the psych package can be used.
Speed = c(20, 40, 50, 60, 100, 120, 150, 200, 1000)
1/mean(1/Speed)
63.08411
library(psych)
harmonic.mean(Speed)
63.08411
Huber M-estimator for location
Another robust estimator for location is the Huber M-estimator. It’s an estimate of the mean using maximum-likelihood estimation and is somewhat robust to outlying values in skewed distributions.
Considering the bacteria data from above,
Bacteria = c(20, 40, 50, 60, 100, 120, 150, 200, 1000)
library(DescTools)
HuberM(Bacteria)
104.9631
A comparison of some location estimators
Again, considering the bacteria data from above,
Bacteria = c(20, 40, 50, 60, 100, 120, 150, 200, 1000)
library(psych)
library(DescTools)
Output = data.frame(
Measure = c("Mean", "Median", "20% Trimmed
mean",
"20% Winsorized mean", "Geometric
mean",
"Huber-M"),
Value = round(c(
mean(Bacteria),
median(Bacteria),
mean(Bacteria, trim = 0.20),
mean(winsor(Bacteria, trim = 0.20)),
geometric.mean(Bacteria),
HuberM(Bacteria))
, 2)
)
Output
Measure Value
1 Mean 193.33
2 Median 100.00
3 20% Trimmed mean 102.86
4 20% Winsorized mean 101.33
5 Geometric mean 98.39
6 Huber-M 104.96
Required readings
[Video] “Understanding Summary statistics: Mean, Median, Mode” from Statistics Learning Center (Dr. Nic). 2015. www.youtube.com/watch?v=rAN6DBctgJ0.
Optional readings
Statistics of location: mean and median
“Statistics of central tendency” in McDonald, J.H. 2014. Handbook of Biological Statistics. www.biostathandbook.com/central.html.
"The median outclasses the mean" from Dr. Nic. 2013. Learn and Teach Statistics & Operations Research. creativemaths.net/blog/median/.
“Measures of the Location of the Data”, Section 2.3 in Openstax. 2013. Introductory Statistics. openstax.org/textbooks/introductory-statistics.
“Measures of the Center of the Data”, Section 2.5 in Openstax. 2013. Introductory Statistics. openstax.org/textbooks/introductory-statistics.
“Skewness and the Mean, Median, and Mode”, Section 2.6 in Openstax. 2013. Introductory Statistics. openstax.org/textbooks/introductory-statistics.
Statistics of variation: standard deviation and range
“Statistics of dispersion” in McDonald, J.H. 2014. Handbook of Biological Statistics. www.biostathandbook.com/dispersion.html.
“Standard error of the mean” in McDonald, J.H. 2014. Handbook of Biological Statistics. www.biostathandbook.com/standarderror.html.
“Measures of the Spread of the Data”, Section 2.7 in Openstax. 2013. Introductory Statistics. openstax.org/textbooks/introductory-statistics.
The normal distribution
[Video] “Normal Distribution” from Statistics Learning Center (Dr. Nic). 2016. www.youtube.com/watch?v=mtH1fmUVkfE.
"The normal distribution – three tricky bits" from Dr. Nic. 2016. Learn and Teach Statistics & Operations Research. creativemaths.net/blog/the-normal-distribution/.
Exercises C
1. Considering Ren and Stimpy's workshops together,
a. How many total attendees were there?
b. How many total workshops were there?
c. How many locations were there?
d. What was the mean number of attendees?
e. What was the median number of attendees?
2. Considering Ren and Stimpy's workshops separately,
a. Which workshops had a higher mean number of attendees, and
what was the mean? Ren’s or Stimpy’s?
b. Which workshops had a higher mean number of attendees, and what was the mean? Ren North or Ren South?
3. Considering Arthur and Buster's workshops together,
a How many students attended in total?
b. How many distinct levels of education were reported?
c. What was the median level of education reported?
d. 75% of students had what level of education or lower?
e. What was the median education level for females?
f. What was the median education level for males?
g. What was the median education level for females from Elwood
County?
h. What was the median education level for males from Elwood County?
4. Considering Arthur and Buster's workshops together,
a. How many students were male?
b. What percentage is this of total students?
c. How many students in the November workshop were male?
d. What percentage is this of total students in the November
workshop?
e. How many male students in the November workshop were from Bear Lake County?
5. As part of a nutrition education program, extension educators had students keep diaries of what they ate for a day and then calculated the calories students consumed. The following data are the result. Rating indicates the score, from 1 to 5, that students gave as to the usefulness of the program. It should be considered an ordinal variable.
Student Teacher Gender Calories Rating
a Tetsuo male 2300 3
b Tetsuo female 1800 3
c Tetsuo male 1900 4
d Tetsuo female 1700 5
e Tetsuo male 2200 4
f Tetsuo female 1600 3
g Tetsuo male 1800 3
h Tetsuo female 2000 3
i Kaneda male 2100 4
j Kaneda female 1900 5
k Kaneda male 1900 4
l Kaneda female 1600 4
m Kaneda male 2000 4
n Kaneda female 2000 5
o Kaneda male 2100 3
p Kaneda female 1800 4
a. What are the variables in this data set and what type of variable is each? (Types are “nominal”, “ordinal”, and “interval/ratio”, not how their types are reported by R.)
For each of the following, answer the question, and show the output from the analyses you used to answer the question.
b. How many students were involved in this data set?
c. What was the mean caloric intake?
d. What was the median caloric intake?
e. What was the standard deviation of caloric intake?
f. What was the mean caloric intake for females?
g. What was the mean caloric intake for females in Kaneda’s class?
h. How many males are in Kaneda’s class?
6. What do you conclude in practical terms about the caloric intake data for
Tetsuo’s and Kaneda’s classes? You might consider the mean or median values
between males and females or between Tetsuo and Kaneda. Think about the real
world. Are the differences you are looking at important in a practical sense?
Be sure to pay attention to the spread of data as you think about this, for example using minimums and maximums, Q1 and Q3 values, or standard deviation values.
Be quantitative in your answer. That is, if you are talking about a difference in medians, mention the actual numerical difference. If expressing values as a percentage makes sense, feel free to do so.